| Comunicaciones |
El proyecto Armeda - Acceso
unificado a bases de datos médicas
a través de la World Wide Web
Holger Billhardt, Víctor Maojo, Fernando Martín*, José Crespo, Alejandro
Pazos**,
Sebastián Alamo, Juan Rodríguez y José Antonio Sanandrés
Grupo de Informática Médica
Dpto. de Inteligencia Artificial, Facultad de Informática, UPM
Campus de Montegancedo. Boadilla del Monte.28660 Madrid.
e-mail: holger@infomed.dia.fi.upm.es
*Instituto de Salud Carlos III
**Universidad de La Coruña
Resumen
El objetivo del proyecto ARMEDA ([1] y [2]) es la creación de herramientas que faciliten una búsqueda unificada de información médica en bases de datos remotas ya existentes. Se parte de la idea de que un conjunto de bases de datos forma un espacio de información único.
Una característica de las bases de datos médicas es la heterogeneidad en su modelo de datos y/o plataforma tecnológica. De este aspecto y del objetivo de crear un sistema abierto y flexible con respecto a cambios y nuevas incorporaciones, surgen tres problemas fundamentales: 1) arquitectura del sistema, 2) unificación de bases de datos con modelos heterogéneos, y 3) interfaz flexible (ajustado al espacio de información accesible en cada momento).
El trabajo presentado introduce una arquitectura distribuida, basada en el estándar de comunicación entre objetos CORBA (Common Object Request Broker Architecture), que permite el acceso a bases de datos remotas a través de la red. Además, se da una breve explicación de la necesidad de crear una teoría de unificación de bases de datos, así como de una interfaz flexible.
1. Introducción
La estandarización de métodos y su sencillez de uso hacen de la World Wide Web (WWW) el medio idóneo para el acceso e intercambio de información. El uso de documentos realizados en HTML (Hyper Text Makup Language) se ha convertido en una norma para la presentación de información en Internet. Existe ya una variedad de herramientas, los llamados buscadores, que guían y apoyan a usuarios en la tarea de búsqueda de información en dichos documentos. Sin embargo, información ya existente en bases de datos tradicionales no está, a priori, accesible desde la WWW. Para su recuperación hacen falta programas CGI (Common Gateway Interface) que resuelven los accesos y convierten el resultado de una petición en un documento HTML. El problema que conlleva este método es la dificultad de realizar búsquedas de información no sólo en un sitio de la red (una base de datos), sino en varios. En esta tarea, en la mayoría de los casos de hoy en día, el usuario tiene que acceder manualmente a cada una de las bases de datos posibles para encontrar la información que busque. El objetivo del proyecto ARMEDA es la solución de este problema en el ámbito médico. Para ello se plantea la creación de herramientas que faciliten la recuperación de información de varias bases de datos médicas, que puedan ser heterogéneas tanto en el esquema o modelo, como en la plataforma en que operan. El fin del proyecto es crear para el usuario la ilusión de trabajar con una única base de datos, donde en realidad está accediendo a un espacio de información compuesto por varias fuentes de datos en diferentes lugares de una Intranet o de Internet. Existen ejemplos de proyectos de investigación sobre sistemas de bases de datos heterogéneas y distribuidas ([3], [4], [5] y [6]) que tratan aspectos similares a los de este proyecto.
Se plantean tres problemas principales para la creación del sistema ARMEDA.
Hasta ahora se han realizado varios prototipos, reflejando una arquitectura que resuelve el problema del acceso a bases de datos remotas. En este artículo se presenta uno de ellos basado en CORBA. A continuación se explica la necesidad de crear un método de unificación sobre bases de datos y de la posibilidad de generar interfaces automáticamente.
Cabe destacar que el proyecto está realizado por investigadores del Grupo de Informática Médica (F.I/U.P.M) y miembros del Instituto de Salud Carlos III. Se plantea la utilización real del sistema como herramienta de acceso y recuperación de los datos de investigación y gestión en aquel instituto.
2. ARMEDA - una arquitectura distribuida
Hay dos componentes de comunicación cuya solución determina la arquitectura principal. Estos son por un lado la comunicación entre el cliente Web y la aplicación ARMEDA, y por otro, la comunicación entre el sistema central y los distintos gestores de bases de datos.
La arquitectura que se propone resuelve estos problemas usando por un lado JavaScript y programas CGI para la comunicación entre el sistema central y el cliente Web, y por otro lado CORBA y ORBs (Object Request Broker) para el acceso del sistema a las distintas bases de datos remotas (gráfico 2).
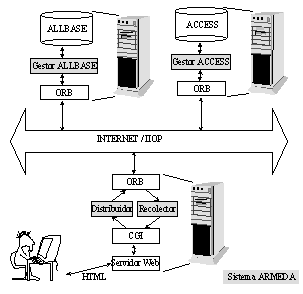
Gráfico 2: Estructura basada en CORBA
En esta propuesta arquitectónica, el sistema ARMEDA está compuesto por páginas HTML incluyendo funciones de JavaScript, unos objetos "Distribuidor" y "Recolector" en el servidor Web, así como por objetos "Gestor" en cada servidor de las bases de datos registradas. Al realizar el usuario una petición de búsqueda a través de una página HTML, las funciones JavaScript incluidas en esta página generan una sentencia SQL (Structured Query Language). Esta se transmite a un programa CGI, que la manda al objeto "Distribuidor". Este objeto distribuye la query a todos los objetos "Gestor" registrados en el sistema, que a su vez realicen la ejecución de la instrucción SQL contra la base de datos que gestionan. Los resultados de la búsqueda son transmitidos al objeto "Recolector" que genera una página HTML para su presentación. Finalmente, se manda esta página al usuario.
La distribución de instrucciones SQL a través del "Distribuidor" se realiza mediante ORBs. Cada objeto "Gestor" se registra en el "Naming Service" del ORB situado en el servidor Web. Por lo tanto, este servicio contiene las referencias de todos los gestores registrados. Cuando el distribuidor recibe una petición (sentencia SQL), accede al servicio de nombres obteniendo estas referencias y, a continuación, transmite la petición a los objetos correspondientes. La comunicación entre los distintos ORBs se realiza mediante el protocolo IIOP (Internet Inter-ORB Protocol), que garantiza su interoperabilidad en la red. Una discusión mas detallada de esta arquitectura se encuentra en [8].
3. Unificación de bases de datos
En el prototipo explicado arriba, las bases de datos, aunque heterogéneas en su tipo, presentan todas el mismo diseño, es decir su esquema es idéntico. Sólo de esta manera es posible la simple distribución de una petición por parte del objeto "Distribuidor", ya que ésta es una sentencia SQL válida para todas las bases de datos registradas. Este método, por tanto, sólo será aceptable cuando se trata de un único esquema común, restricción demasiado fuerte en la mayoría de los casos. Normalmente, las bases de datos, aunque mantienen información sobre el mismo dominio, soportan esquemas o modelos distintos.
Para la solución de este problema y, por tanto, la posibilidad de realizar accesos a bases de datos con diseños distintos, es preciso crear un repositorio virtual que integre todas las fuentes de información existentes. Al igual que los objetos "Gestor" representan en realidad una base de datos, el objeto "Distribuidor" podría representar este repositorio virtual. Eso significa que este objeto debe soportar un esquema (el esquema común o unificado de las bases de datos reales), y debe ser capaz de resolver peticiones contra este esquema. Mientras la resolución de peticiones en un objeto "Gestor" significa la ejecución de sentencias SQL en la base de datos correspondiente, en el objeto "Distribuidor" significaría la traducción de la petición a instrucciones SQL y su distribución a los objetos "Gestor".
Son tres las tareas a resolver a este respecto: 1) definir un modelo común de representación de bases de datos, 2) definir una teoría de unificación sobre este modelo, y 3) definir un lenguaje para realizar peticiones y el algoritmo de traducción de este lenguaje a SQL.
4. Interfaz automática
Como se ha comentado anteriormente, la flexibilización del sistema hacia modelos de datos heterogéneos, conlleva la necesidad de proporcionar una interfaz de usuario adaptable a la información accesible en cada momento. Para ello es preciso que la representación de una base de datos (virtual o real) en el sistema debe ser auto-explicativa, es decir, que cualquier usuario podría deducir de ella el dominio y la estructura de datos soportados. En este sentido es importante que los nombres empleados para denominar los distintos elementos de una base de datos (clases, atributos y relaciones) también sean auto-explicativos. Una clase que refleja enfermedades, por ejemplo, debe llamarse "Enfermedades" y no de otra manera. Cumplido este criterio, los esquemas representados podrían servir para la generación de interfaces amigables de una manera automática. Estas interfaces, basadas en páginas HTML, permitirán a los usuarios la recuperación de los valores de atributos de una clase seleccionada, y la "navegación" entre las clases a través de relaciones. Aquí, los nombres de clases, atributos y relaciones pueden servir a su vez como nombres para los enlaces en las páginas HTML.
5. Conclusiones
El acceso a bases de datos remotas y heterogéneas a través de Internet presenta tres problemas fundamentales: una arquitectura distribuida para resolver el acceso a bases de datos remotas, la unificación de bases de datos con diseños distintos, y, por último, la generación automática de una interfaz de usuario amigable, que facilita el acceso de una manera uniforme al espacio de información accesible. Se ha presentado un prototipo del sistema ARMEDA que está basado en una arquitectura CORBA y resuelve los accesos a distintas bases de datos remotas y heterogéneas, en cuanto a la plataforma tecnológica se refiere. Esta arquitectura es aplicable en todos los casos donde las bases de datos presentan el mismo esquema interno.
En el apartado 3 se ha explicado que, manteniendo la estructura distribuida de este modelo, pero ampliando su parte central, se puede obtener la posibilidad de acceso a bases de datos con diseños distintos. Para ello es preciso definir: 1) un modelo común de representación de esquemas, 2) una teoría de unificación sobre este modelo, y 3) un lenguaje de peticiones.
Otro aspecto importante para mantener la flexibilidad del sistema es la posibilidad de generar interfaces amigables automáticamente. En el apartado 4 se ha explicado que la representación de bases de datos en el sistema debe ser auto-explicativa, y así puede servir en esta tarea.
Nuestro trabajo en el futuro se centrará en los aspectos de unificación de bases de datos con diseños heterogéneos. Se plantea la incorporación de esta facilidad al sistema existente y su implantación en el Instituto de Salud Carlos III para resolver el acceso a las bases de datos de este instituto en una Intranet. A mas largo plazo se propone la integración de otros servicios, como por ejemplo el acceso a un servidor de vocabulario médico que se esta desarrollando en nuestro grupo. De esta manera, el sistema ARMEDA se podría convertir en una herramienta general para la búsqueda, acceso y recuperación de información médica a través de Internet.
6. Agradecimientos
El hardware y software utilizados para el presente proyecto han sido donados por la compañía Hewlett-Packard bajo la iniciativa HISE (Healthcare Information Systems Engineering) 1996. Diversos aspectos de este proyecto han sido financiados en parte, gracias a los proyectos FIS 97/0267 y CICYT TEL97-1073-C02-01.
7. Referencias
[1] Alamo, S., Crespo, J; Fernández, I.; Maojo, V.; Martín, F.; Pazos, A; Sáez, L.; Sanandres, J.: "Búsqueda, acceso y recuperación de información sanitaria en bases de datos heterogéneas a través de la World Wide Web", Comunicaciones del Congreso INFORSALUD 97. Sociedad Española de Informática de la Salud. Madrid, 1997.
[2] Fernández, I.; Maojo, V.; Crespo, J.; Alamo, S.; Sanandrés, J.; Martín, F.: "ARMEDA: Accessing Remote Medical Databases over the World Wide Web", Proceedings of Medical Informatics Europe 1997. Porto Carras, Greece, 1997.
[3] Stonebraker, M.; Aoki, P.M.; Pfeffer, A.; Sah, A.; Sidell, J.; Staelin, C.; Yu, A. : "MARIPOSA: A Wide-Area Distributed Database System". http://sunsite.berkeley.edu/NCSTRL.
[4] Rusinkiewicz, M. et al : "The InfoSleuth Project", http://www.mcc.com/projects/infosleuth/.
[5] Ohno-Machado, L.; Boxwala, A.A.; Ehresman, J.; Smith, D.N.; Greenes, R.A. : "A Virtual Repository Approach to Clinical and Utilization Studies: Application in Mammography as Alternative to a National Database". Proceedings of the 1997 AMIA Annual Fall Symposium, edit. Daniel R. Masys, 1997.
[6] Dogac, A. et al : "MIND: METU INteroperable Database Management System". http://srdc.metu.edu.tr/mind/
[7] Siegel, J. : "CORBA Fundamentals and Programming", John Wiley & Sons, Inc., 1996.
[8] Alamo, S. : "Armeda: Acceso Remoto a Bases de Datos Medicas a través de Internet". Proyecto de fin de carrera, Universidad Politécnica de Madrid, 1998.
