Informática y Salud
Nş 38. Noviembre 2002
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas]
|
|
Informática y SaludNş 38. Noviembre 2002 |
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas] |
||
|
Secretaría Técnica: CEFIC
|
ESPECIAL BIOINFORMÁTICA Informática Biomédica en
Oncología. Aurelia Bustos Moreno Fernando Martín Sánchez Resumen Palabras clave: Informática Biomédica, integración de datos, imagen médica, bioinformática, epidemiología, informática clínica
I. Introducción El objetivo del presente artículo es describir el ámbito de las aplicaciones de la informática biomédica en los diferentes campos de la Oncología desde su desarrollo en la investigación básica y clínica del cáncer hasta en la asistencia integral al paciente oncológico y gestión de la información biomédica. La informática biomédica en Oncología se define como la aplicación de las ciencias computacionales y las tecnologías de la información para la obtención, representación, procesamiento y gestión de conocimiento e información en las ciencias de investigación en cáncer y en el ámbito clínico. Por un lado aporta la metodología y herramientas necesarias para tratar de avanzar en la comprensión del cáncer desde sus bases moleculares comenzando por el DNA, pasando por las proteínas, vías de seńalización celular, procesos del metabolismo, patología clínica del cáncer hasta sus aspectos epidemiologicos. Por otro lado ofrece la infraestructura necesaria para la translación de los avances en la investigación en el beneficio clínico del paciente oncológico y de la sociedad. Las aplicaciones de la informática biomédica tratan de integrar la información genética y molecular del cáncer con los datos clínicos y epidemiológicos. El desarrollo integrado de las aplicaciones marca la tendencia actual con implementaciones basadas en sistemas multiplataformas ejecutados en red, escalables, modulares y reusables, capaces de adaptación a múltiples entornos y a diferentes funcionalidades y basados en estándares para maximizar la comunicación y el acceso a información de forma universal. El cáncer es una entidad compleja. La progresión desde el tejido normal hasta el cáncer invasivo está dirigida por cambios en el DNA celular influenciado por factores genéticos hereditarios así como cambios genéticos somáticos. Para su comprensión se requiere un enfoque multidisciplinar de investigación básica, clínica y de poblaciones que abarque desde los mecanismos que conducen a la carcinogénesis, la progresión en cáncer, los fenómenos fisiológicos y metabólicos llegando hasta la expresión clínica del cáncer en el paciente y por último hasta su comportamiento en el ámbito de poblaciones y su interacción con agentes externos ambientales La informática biomédica tiene por objetivo el estudio del flujo de información entre la biología y la medicina (Altman 2001) desde los genes hasta las poblaciones. La estructura del presente artículo seguirá la dirección de este flujo, introduciendo los aspectos más relevantes de la informática biomédica aplicada a la biología molecular del cáncer, a la farmacogenómica, las nuevas técnicas de imagen en cáncer, información clínica y aisitencial y aspectos epidemiológicos y poblacionales.
II. Proyectos e iniciativas actuales En este apartado se revisan algunos de los desarrollos más importantes en Informática Biomédica del Cáncer en Estados Unidos y en la Unión Europea. A) Estados Unidos El "National Cancer Institute" (NCI) está desarrollando una infraestructura informática para maximizar el intercambio de información y recursos entre investigadores. La infraestructura informática está formada por tres módulos: 1. Un núcleo de procesamiento de conocimiento que trabaja para estandarizar la información y su empleo por todos los proyectos del NCI. 2. Herramientas basadas en las tecnologías de la información que comuniquen con dicho núcleo y permitan la captura, el análisis y la reutilización de la información. 3. Expertos de diversas áreas de la investigación científica, incluyendo informática, que apliquen estas herramientas para la resolución de problemas en la investigación en cáncer y en la práctica clínica. Se crearán interfaces electrónicas entre investigadores poniendo en estrecho contacto a las comunidades que llevan a cabo investigación básica, translacional, clínica y de poblaciones. Se espera que dicha infraestructura mejore la translación de las observaciones científicas en intervenciones clínicas y de salud pública. El proyecto del NCI abarca todas las áreas de conocimiento en cáncer. Uno de los ejemplos de la magnitud de dicho proyecto es el CGAP (Cancer Genome Anatomy Project ) http://cgap.nci.nih.gov/ . Se trata de un programa interdisciplinario que ofrece la información y las herramientas tecnológicas necesarias para descifrar la anatomía molecular de la célula tumoral mediante la determinación de los perfiles de expresión génica de células normales, precancerosas y cancerosas. El Centro Nacional de Información sobre Biotecnología (NCBI) http://www.ncbi.nlm.nih.gov/ ha desarrollado las herramientas y ha llevado a cabo su implementación. La información está organizada en tres secciones: 1) Aplicaciones de acceso y análisis a los datos genómicos en humanos y ratones: a. Genefinder busca los genes basado en varios criterios de búsqueda y los vincula con información de diferentes sases de datos con información sobre los ESTs (expressed sequence tags), patrones de expresión genética, SNPs, ensamblaje de clusters e información citogenética b. GO- Browser clasifica los genes humanos y de ratón según la función molecular, el proceso biológico y los componentes celulares en los que están implicados. c. BLAST es una herramienta de búsqueda de genes basado en similitudes en las secuencias de nucleótidos. d. Library Finder es un buscador de librerias de cDNA. También incluye diversas herramientas para examinar la expresión génica de algunas librerias de cDNA. 2) Aplicaciones para el estudio de los cromosomas e. Mittelman Database es un mapa que muestra las localizaciones conocidas de las aberraciones cromosómicas en el cancer humano e incorpora entre otras herramientas de búsqueda de SNPs según cromosoma y tipo de cáncer. 3) Diagramas de rutas moleculares en cáncer y complejos de proteínas con vínculos a fuentes de información genética para cada proteina/enzima conocida. Entrez (http://www.ncbi.nlm.nih.gov/Database/index.html) es un sistema de búsqueda y recuperación de información que integra secuencias de nucleótidos, proteínas, estructuras macromoleculares, genomas completos, y literatura científica. Facilita el acceso y el análisis de las múltiples bases de datos vinculadas entre sí. B) EUROPA El Quinto Programa Marco de Investigación aprobado por la Comisión Europea de Investigación Comunitaria para el ańo 2002, incluye, dentro del programa de Tecnologías de la Sociedad de la Información (IST) un área de aplicaciones para la salud. Algunos de los proyectos de especial interés para la Oncología aparecen en la Tabla I. En el Reino Unido, el Cancer Genomic Project financiado por la entidad privada Wellcome Trust llevará a cabo en el Sanger Institute un programa de identificación de los genes implicados en el desarrollo de tumores humanos. El proyecto cuenta con una potente infraestructura bioinformática que dará soporte a las diferentes fases del estudio.
Tabla I. Proyectos del programa de Tecnologías de la Sociedad de la Información (IST) 2001 de la CE de especial interés en Oncología
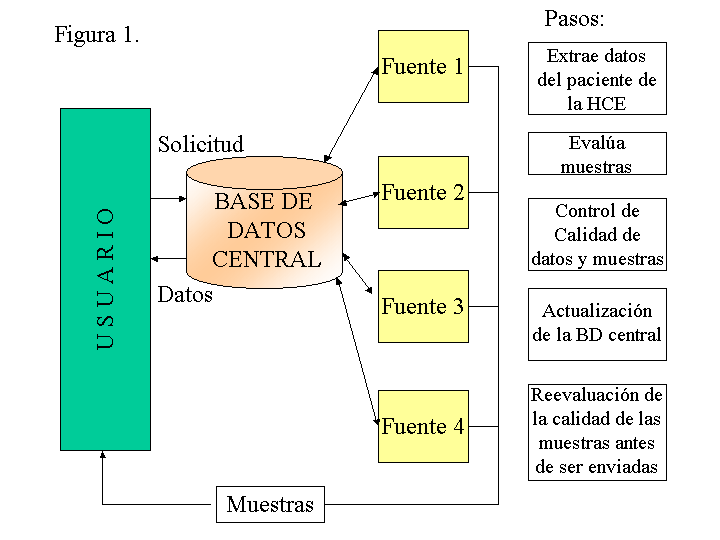
III. Tratamiento de información genómica en Oncología La comprensión de la biología molecular del cáncer requiere la integración de la genómica, la proteómica, la biología celular y la medicina clínica. La genómica y proteómica del cáncer estudian el conjunto de todos los genes y proteínas respectivamente mediante herramientas computacionales. La genómica y la proteómica hacen posible la caracterización masiva de genes y proteínas asociados con el desarrollo del cáncer gracias a: Nuevos enfoques experimentales basados en biochips (chips de material biológico de alta densidad de integración) Acceso universal a bases de datos de información biológica en Internet Desarrollo de software de almacenamiento, búsqueda, minería de datos y de representación de conocimiento. Las áreas actuales de investigación son: Desarrollo de una taxonomía molecular de los tumores. Exploración de las consecuencias moleculares de la activación de los oncogenes mediante la genómica y proteómica. Desarrollo de marcadores genéticos para diagnóstico precoz y para pronóstico de cáncer. El principal objetivo de la genómica del cáncer es la identificación de los genes cuya expresión está implicada en el desarrollo y progresión del cáncer. Solo una pequeńa proporción del genoma contribuye realmente en los genes expresados y en los elementos reguladores. Se cree que de los 30.000 a 40.000 genes estimados que componen el genoma humano (NCBI), menos de 10.000 son expresados en las células de un determinado tejido y de estos se estima que de unos 500 a 1000 están implicados en la carcinogénesis y desarrollo tumoral (Wellcome Trust). La proteómica del cáncer permite la identificación y análisis cuantitativo de las proteínas expresadas de forma diferencial en tejido normal y en los diferentes estadios del cáncer desde las lesiones preneoplásicas hasta las neoplasias. La proteómica da respuestas sobre la estructura de la proteína, su función y localización celular. También estudia las modulaciones de la expresión y función de las proteínas, las interacciones entre proteínas y los sistemas de rutas de transducción de seńales que regulan el funcionamiento celular (p.ej: el metabolismo, la división celular, la muerte, la diferenciación y el movimiento). Los sistemas de gestión de información de laboratorio (LIMS) organizan y procesan un largo número de muestras de pacientes, tejidos, líneas celulares y genes individuales y productos génicos. A pesar de que se han desarrollado sistemas de gestión de los datos de laboratorio que ofrecen una interfaz con las bases de datos públicas (2), es necesaria la incorporación y gestión de información clínica heterogénea. a) Biochips e Identificación de marcadores tumorales La identificación de marcadores genéticos se consigue comparando los perfiles de expresión de diferentes tipos de muestras. Cuando las muestras corresponden a diferentes estados patológicos del mismo tejido o subtipos del mismo tumor, los patrones de transcripción clasifican los tumores basados en una perspectiva molecular en lugar de morfológica. Además, los perfiles de expresión presentan un potencial para la identificación de rutas de seńalización en cáncer que podrán ser dianas de tratamiento (3). Los biochips son dispositivos de reducido tamańo con material biológico fijado a una superficie sólida que se utilizan para la monitorización de grandes volúmenes de información biológica en paralelo. El análisis de la información que generan los biochips precisa de herramientas bioinformáticas. Los biochips proporcionan una amplia gama de aplicaciones en la clínica y en la investigación en cáncer: Biochips de detección de polimorfismos (SNPs) para la investigación de predisposición genética. Biochips de cDNA (secuencias de DNA obtenidas a partir del RNAm) para el análisis de los perfiles de expresión globales. Biochips con CGH (Hibridación Genómica Comparativa) para el screening de alteraciones genéticas en células cancerosas. Biochips de proteínas para el análisis de las concentraciones, actividades funcionales e interacciones entre proteínas. Biochips de tejidos (Tissue arrays) para analizar el comportamiento molecular de diferentes muestras tisulares y tumores. Una importante aportación sobre la correlación entre los patrones de expresión de genes con la evolución clínica ha sido realizada por Alizadeh et al.(4). Este estudio asocia la variabilidad en la historia natural del Linfoma B de células grandes difusas con perfiles diferentes de expresión génica utilizando arrays de DNA. Los perfiles de expresión discriminan un grupo con mayor supervivencia. A raíz de este estudio Davis R et al (5) determinan una ruta específica de seńalización como indispensable para la supervivencia de las células del subtipo de linfoma de peor pronóstico. Su inhibición causa la muerte celular y por tanto es un potencial blanco de tratamiento para el subtipo de linfoma de células B con peor pronóstico. El estudio de Sorlie et al (6) basándose en los patrones de expresión génica clasifica el cáncer de mama en un grupo similar al epitelio basal con peor pronóstico, un grupo con sobreexpresión de ERBB2 y un grupo similar a la mama normal. Además las pacientes con positividad para receptores de estrógenos se pueden dividir en al menos dos grupos con diferencias significativas en supervivencia. En otro estudio (7) 67 tumores de pulmón fueron examinados utilizando un microarray de cDNA de 24.000 elementos. La subdivisión de los tumores basada en los patrones de expresión se correlacionaba fielmente con la clasificación morfológica de tumores escamosos, de células grandes, células pequeńas y adenocarcinomas. Además, el análisis de los patrones de expresión permitía subdividir los adenocarcinomas en subgrupos con diferencias significativas en la supervivencia de los pacientes. Similares estudios se han realizado para clasificar a nivel molecular tumores de mama hereditarios (8) y leucemias (9). Esto proporciona evidencia de que la clasificación de los tumores en categorías generales de expresión génica puede identificar subtipos de cáncer con comportamiento clínico diferente y que hasta ahora eran morfológicamente indistinguibles. Los arrays de tejidos es otra nueva tecnología clave en Oncología. Una vez que un supuesto marcador o conjunto de marcadores es identificado mediante arrays de cDNA de muestras de tejido tumoral, el siguiente paso es la validación de estos marcadores en una gran población de tejidos humanos. Hasta la fecha se ha venido realizando mediante técnicas de microscopía óptica e inmunohistoquímica, lo que requiere una laboriosa tarea de tinción de cientos de muestras. Este proceso exhaustivo ahora se puede realizar en una sola superficie. El microarray de tejido consiste en 1000 biopsias cilíndricas de tejido, cada una de un paciente diferente, distribuidas de forma conocida sobre una superficie. Cada tumor es representado por una sección de 0.6 mm de diámetro y 4 – 8um de espesor. La automatización de la creación de los arrays de tumores acelerará la correlación de marcadores en estudios con grandes tamańos muestrales. El NCI en colaboración con el National Human Genome Research Institute ha organizado un programa de investigación (TARP) para el desarrollo de microarrays de tejidos de múltiples tumores. En ellos se pretende la caracterización de los tipos de tumores según los perfiles de expresión de DNA, RNA, y proteínas, y la caracterización de moléculas como potenciales dianas moleculares específicas de cada tumor. A inicios del 2002 ya se han distribuido aproximadamente 11000 arrays a diversos centros de investigación nacionales. El programa está trabajando en una producción a mayor escala de dichos arrays. La tecnología de los arrays también se están aplicando en proteómica. Paweletz et al. (10) ha utilizado un biochip de proteínas que clasifica poblaciones de proteínas por pesos moleculares para mostrar patrones de proteínas que diferencian tejido normal, premaligno, y células malignas obtenidas mediante técnicas de microdisección de tejido humano. En el futuro las tecnologías de arrays en proteómica podrán utilizarse para la generación rápida de perfiles de rutas de seńalización. Se espera que se pueda determinar el estado de rutas celulares que controlan mitogénesis, apoptosis (muerte celular programada) y otras rutas funcionales. El flujo de información a través de estos circuitos de forma separada o combinada, podrá en un futuro dictar el comportamiento clínico y la susceptibilidad a tratamiento. Por último, seńalar que el requisito principal para que la identificación de marcadores genéticos se use en sistemas de soporte a la decisión clínica (diagnóstico, pronóstico y monitorización) es que el sistema tenga capacidad de generalización a todas las muestras. Para ello se utilizan conjuntos de expertos para seleccionar dentro de un perfil genético el subgrupo de genes más representativo (11). CLEAVER (http://classify.stanford.edu/) es una página de Internet creada por la Universidad de Stanford que ofrece gratuitamente una variedad de herramientas de ayuda en el análisis de los datos de expresión de los microarrays. Facilita herramientas de visualización, clasificación y clustering de los datos. Patrones de expresión de los genes implicados en resistencia a fármacos. Los biochips también están siendo empleados para la decisión de estrategias terapéuticas individualizadas de acuerdo con el perfil de expresión. El estudio realizado por Veer LJ et al. (12) en el que mediante un microarray de DNA analizaron 117 cánceres primarios de mama e identificaron un perfil de expresión que predice un corto intervalo hasta el desarrollo de metástasis a distancia en el subgrupo de pacientes con ganglios negativos. Dicho perfil de expresión consiste en genes que regulan el ciclo celular, invasión, metástasis y angiogénesis. El perfil de expresión génica parece superar los factores pronósticos clásicos tales como el estado ganglionar y el grado histológico y podría ser una estrategia de selección de pacientes que se beneficiaran de tratamiento adyuvante con quimioterapia. Diagnóstico precoz del cáncer Las nuevas técnicas experimentales basadas en biochips también están siendo aplicadas en la identificación y desarrollo de nuevos marcadores para diagnóstico precoz de cancer. El EDRN (Early Detection Research Network) está realizando avances significativos en este campo. En cáncer de mama, mediante un biochip de proteínas, han encontrado diferencias en los patrones proteicos en el fluido de los ductos de las mamas afectas y normales. La extracción de fluido mediante aspiración por el pezón es una técnica no invasiva y sencilla, por ello se está validando como técnica de detección precoz en un gran número de especímenes. En cáncer de esófago, según datos preliminares, los patrones de expresión obtenidos mediante microarrays de DNA detectan lesiones premalignas y malignas con gran precisión. En caso de confirmarse, los patrones de expresión podrían potencialmente clasificar las lesiones por su agresividad y su respuesta a una posible quimioprevención. Sistemas informatizados de bancos de tumores Las muestras de tejido significan un recurso crítico para la investigación y aplicación de marcadores moleculares en la detección, diagnóstico y tratamiento del cáncer. Actualmente existen varios proyectos de realización de bancos informatizados de tumores. (Fig. 1)
La Universidad de Pittsburgh dentro del programa de Informática en Patología, está desarrollando e implementando un sistema informatizado de banco de tumores. En una primera fase, están trabajando en la adquisición de los datos a partir de los sistemas existentes almacenados en el banco de tejidos –clínico (texto), -morfológico (imagen) y -genómica (microarray). En una segunda fase están desarrollando herramientas para permitir a los investigadores hacer consultas y visualizar en este gran conjunto de datos la información específica según los parámetros definidos por los usuarios (Ej.: tejido prostático con adenocarcinoma mostrando microinvasión y alta actividad de STK2). El desarrollo de este sistema requiere de estudios empíricos para determinar los mecanismos más eficientes para almacenar, representar y consultar este gran conjunto de datos multimedia. Pretenden obtener un producto apto para el entorno médico, farmacéutico, de bioingeniería y de genómica. El NCI ha puesto ha disposición de los investigadores una variedad de repositorios de tejidos. La red compartida Shared Pathology Informatics Network es un consorcio de instituciones conectadas por un sistema Web. El sistema ofrece acceso a información de las bases de datos médicos y de los repositorios de información de anatomía patológica según unos criterios de búsqueda, eliminando la información que pueda comprometer la privacidad del paciente. La información incluirá datos sobre demografía, información diagnóstica, estado vital, historia clínica y de evolución del paciente en caso factible. El nombre del paciente y otros datos identificadores son encriptados o bien son modificados. El sistema pretende ofrecer a los investigadores una respuesta rápida sobre la disponibilidad de especímenes con las características especificadas.
IV. Tecnologías de imagen en cáncer Hasta la fecha se han desarrollado múltiples sistemas informatizados de ayuda al diagnóstico por imagen. Los sistemas computerizados de análisis de imagen (CAD) han mostrado ser una herramienta que ayuda a la detección de tumores y entre ellos el cáncer de mama. Desde un 10% a un 30% de los cánceres de mama no detectados en las mamografías, son potencialmente detectados con los CADs (13). Los sistemas utilizan algoritmos que detectan áreas sospechosas y generan un informe del examen de screening resaltando hallazgos como masas, desestructura de la arquitectura, densidades asimétricas y microcalcificaciones. Los CADs son utilizados como segundas opiniones que pueden ayudar al radiólogo a confirmar la detección de un área sospechosa o a identificar aquellas que puedan haberle pasado desapercibidas (14). También se han desarrollado sistemas de soporte a la decisión que incrementan la precisión del diagnóstico no invasivo de tumores cerebrales (15). Estos sistemas, que utilizan técnicas de reconocimiento de patrones, han sido entrenados con bases de datos de espectros validados e información clínica asociada para proporcionar una clasificación automática de los tumores cerebrales. Otros proyectos relevantes son los sistemas de almacenamiento virtual de las imágenes de las muestras de tejido de los servicios de anatomía patológica. En concreto la Universidad de Pittsburgh (http://path.upmc.edu/divisions/informatics.html) está estudiando sistemas de alta velocidad de compresión de imagen manteniendo a su vez una alta definición. También están evaluando la fiabilidad de los sistemas de robótica para captura de imágenes a partir de las muestras, la utilidad clínica del mantenimiento de estas grandes bases de datos conteniendo las imágenes y las potenciales utilidades diagnósticas de estos sistemas vs. al clásico método de cristales. Sistemas de imagen molecular Los sistemas de imagen molecular pueden definirse como la representación a nivel molecular de los procesos biológicos en un organismo vivo. (16, 17). Combinan la información genética y las propiedades químicas para crear nuevos marcadores que son detectables mediante tecnologías sofisticadas de imagen. Las técnicas de imagen molecular detectan seńales que indican la presencia de actividad bioquímica y cambios tales como la replicación celular o la muerte celular. La imagen molecular frecuentemente es descrita como sistemas de imagen funcional debido a que los procesos que reflejan están activos o en continuo cambio. Se trata de una nueva área de investigación en cáncer que involucra a ingenieros biomédicos, químicos, biólogos moleculares y celulares, farmacólogos e informáticos expertos en imagen.
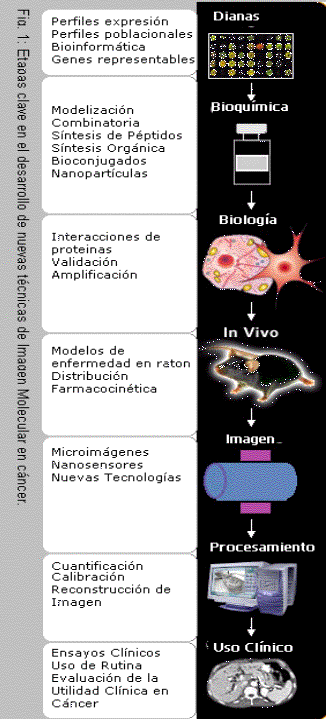
El proceso de desarrollo comprende desde la identificación de la diana hasta su puesta en práctica para uso clínico (Fig. 2). 1. En primer lugar se utilizan herramientas bioinformáticas para la detección de las dianas moleculares que se encuentran sobreexpresadas en cáncer. Se diseńa el software para realizar búsquedas en las bases de datos con una base estructural para la identificación de motivos que puedan ser representables por imágenes tales como receptores que se internalizan o proteasas. En los casos particulares de tumores con poca información en las bases de datos, se realizan perfiles de expresión con técnicas como biochips para analizar sobreexpresión o expresión de genes específicos para el tumor. Con los perfiles poblacionales se determina en que grado el gen o el conjunto de genes escogidos están representados en la población afecta y sana. 2. Mediante tecnologías de clonado, RNM o ensayos espectrales se identifican genes que potencialmente pueden ser representables. 3. Mediante síntesis de péptidos se obtienen conjugados pépticos teńidos. La síntesis orgánica permite sintetizar nuevos colorantes para imagen óptica, bioconjugados y conjugados de nanopartículas magnéticas. En los casos en los que las dianas son macromoléculas en los que se conoce la estructura de la secuencia se puede modelar tanto la diana como los agentes de imagen. 4. Con frecuencia los ligandos o receptores son sobreexpresados en los tejidos tumorales y pueden ser utilizados para interaccionar con los agentes de imagen. La conjugación de los agentes con ligandos naturales también puede generar tests útiles de imagen. La utilidad de un receptor como diana de imagen es dictada por la tasa y el grado con los que interacciona con el agente de imagen. La amplificación de seńales ocurre cuando el agente utilizado para la imagen cambia las propiedades al entrar en interacción con la diana. Por ejemplo el agente genera seńales debido a la acción de una enzima al interaccionar con ella o mediante la internalización de un receptor. 5. Mediante modelos de ratón se estudia la farmacocinética y la distribución de los agentes de imagen así como las vías de administración más apropiadas. 6. La reconstrucción de la imagen en 3D requiere de software específico y métodos de fusión de imágenes para integrar las seńales con las localizaciones anatómicas. Entre las técnicas de imagen caben destacar la microimagen con RNM, TC, Gamma grafía, SPECT, PET, bioluminiscencia, fluorescencia y microscopia intracavitarias. 7. En una etapa final se evalúa a nivel clínico su capacidad de detección precoz del tumor incluyendo estados premalignos o su capacidad de evaluación directa de tratamientos antitumorales. Algunas de las áreas de investigación en cáncer son: Representación por imagen de procesos específicos celulares y moleculares y las interacciones entre proteínas dentro de rutas de seńalización celulares. Representación por imagen de la amplificación selectiva de genes terapéuticos Monitorización de la circulación y dianas de células T genéticamente modificadas Representación por imagen del crecimiento y vascularización de tumores in vivo El uso de la espectroscopia por RNM y PET para optimizar la quimioterapia y terapia génica. Una de las técnicas en desarrollo son los llamados contrastes inteligentes. Cuando el contraste es inyectado en sangre es indetectable, sin embargo cuando se unen a proteasas expresadas en tumores, las moléculas de contraste cambian la configuración y se hacen fluorescentes. La seńal fluorescente es detectada mediante dispositivos especiales. Estas técnicas se prevé que tengan en el futuro aplicaciones importantes en la detección de tumores y en el tratamiento. In Vivo Cellular and Molecular Imaging Centers (ICMICs) es una asociación de centros bajo la organización del NCI que están liderando la investigación en esta área. Un ejemplo gráfico de la potencial utilidad de la imagen molecular en el tratamiento del cáncer es el desarrollo de una técnica específica de predicción de respuesta a 5-Fluorouracilo (5-Fu) mediante PET. Recientemente investigadores de Heidelberg han comunicado una correlación positiva entre la respuesta del tumor al 5-FU y la captación tumoral de 5-Fu marcado (18F) en las imágenes del PET de pacientes en tratamiento por cáncer de colon metastásico. Basado en estos datos actualmente se está desarrollando en la Universidad de Carolina del Sur un método capaz de medir el transporte y el metabolismo del 5FU. El objetivo es predecir respuesta al tratamiento según la medida de captación. También se propone medir los niveles de timidalato sintetasa (asociado con la resistencia a FU) y relacionarlos con los niveles de captación de Fu marcado. Recientemente se ha demostrado la viabilidad de la representación por imagen de la expresión transgénica in vivo. En un reciente estudio (18) han desarrollado un vector adenoviral conteniendo el gen transgénico y un gen detectable óptimamente mediante bioluminiscencia. Como resultado han podido correlacionar la respuesta del tumor al tratamiento por resonancia magnética con la localización, magnitud y duración de la expresión transgénica detectada mediante bioluminiscencia in vivo. Otros proyectos (19) liderados por el Instituto de Tecnología de Massachusetts evaluarán la hipótesis de que mutantes enzimáticos de diseńo puedan ser utilizados como catalizadores eficientes de la conversión de prodrogas y como sistemas enzimáticos marcadores de imagen. V. Farmacogenómica en cáncerEl objetivo de la farmacogenómica es contribuir al descubrimiento de la causas del cáncer y al desarrollo de agentes que específicamente actúen sobre estas causas con el fin de tratar y prevenir el cáncer. Hasta ahora la investigación de fármacos antitumorales se ha basado en el rastreo empírico de compuestos químicos. El desarrollo de fármacos en el siglo XXI se basará en el conocimiento de las bases moleculares del cáncer. Los nuevos fármacos son sintetizados con la intención de que interactúen en algún punto concreto clave del desarrollo del cáncer. Ejemplos de dianas en las que actuan dichos agentes son: angiogenesis, invasión y metástasis y otros procesos microambientales; transducción de seńales; control del ciclo celular; apoptosis; inmunoefectores; antimutagenesis (por ejemplo mutaciones reversas en genes diana mutados) y elementos antioxidantes. Una comprensión sistemática de los sistemas de genes y proteinas que modulan la respuesta al fármaco será un factor clave para asegurar que el tratamiento antitumoral será eficaz y estará exento de efectos secundarios (20). Aunque no se sabe cuantos genes de los 35000 que aproximadamente se estiman en el genoma humano son relevantes para la respuesta a drogas, un análisis preliminar (PharmGKB) indica que podrán ser desde unos 500 a unos 1000 genes. Aunque la delimitación del área de conocimiento de la farmacogenética y farmacogenómica es algo polémica es importante introducir ambos términos. La farmacogenética es el estudio de cómo la variación en genes individuales afecta la respuesta a drogas. Ha existido como campo desde hace más de cuatro decadas y ha contribuido a la comprensión de fenómenos tales como las respuestas idiosincrásicas a opiáceos y agentes antitumorales. La farmacogenómica es una disciplina reciente que estudia el conjunto completo de genes farmacológicamente relevantes, como manifiestan sus variaciones, como estas variaciones interactuan para producir el fenotipo y como el fenotipo afecta la respuesta al tratamiento. (21) Distiguimos diferentes niveles de evidencia en farmacogenómica. (PharmGKB http://pharmgkb.org/do/serve?id=home.welcome) Genotipo a. Demostración de una variabilidad en la secuencia de los genes, tales como SNPs, delecciones e inserciones. Fenotipo b. Test funcionales: Demostración de una correlación de los diferentes genotipos con distintas funciones genéticas, tales como los productos de expresión génica, rutas moleculares y efectos a nivel celular. c. Farmococinética: Demostración de la asociación de la variabilidad genética con cambios en parámetros como los niveles en sangre, tasa de metabolismo y excrección del fármaco. d. Farmacodinámica y respuesta clínica a drogas. Se demuestra un efecto medible clínicamente en respuesta a las diferencias genéticas. Las diferencias genéticas pueden ser propuestas como marcadores de respuesta clínica. e. Pronóstico del paciente: Se demuestran diferencias significativas en los pacientes que reciben un tratamiento específico en función de la variabilidad genética respecto al intervalo libre de progresión, calidad de vida, supervivencia etc., Por ejemplo la sobrexpresión del RNA mensajero del gen ERCC1 ha demostrado en diferentes estudios una supervivencia significativamente menor en enfermos tratados con CDDP u Oxaliplatino. La farmacogenómica se sustenta sobre herramientas informáticas para la integración de la información de la biología molecular del cáncer (secuencias, estructuras, rutas moleculares de control del ciclo celular, apoptosis, sistemas de reparación del DNA etc,.) de la medicina clínica (tratamientos, historia clínica, efectos secundarios, respuestas clínicas a tratamientos) y de la farmacología (farmacocinética y farmacodinámica). La farmacogenómica utiliza muchas de las herramientas bioinformáticas (p.ej: instrumentos de búsquedas en bases de datos de DNA, técnicas de comparación de secuencias con genomas conocidos de otros organismos para la identificación de nuevos genes, utilización de microarrays para la detección de variación genética como los SNPs y para la medida de cambios medibles en la expresión de los genes en respuesta a drogas, búsquedas en bases de datos para asociación de genes con fenotipos relacionados etc,), pero además necesita incorpora herramientas para la organización de la información clínica. Un ejemplo gráfico en el que se integran datos de diferentes áreas es el estudio de Scherf et al. (22) en el que se combina la información de los microarrays con otros conjuntos de datos. En este estudio se midieron los niveles de expresión de los genes de 60 líneas celulares procedentes de diferentes tumores y se compararon con las sensibilidades de cada una de estas líneas celulares a 70.000 potenciales tratamientos antitumorales. Se definieron los patrones de expresión que identificaban la sensibilidad potencial a las drogas antitumorales y las líneas celulares se agruparon en base a las potenciales sensibilidades. Se espera que los experimentos con microarrays de células antes y después de ser expuestas al tratamiento, proporcionen información farmacogenómica para la determinación del conjunto completo de cambios que ocurren a nivel celular así como a nivel farmacocinético (23). Además de la comprensión de la regulación a partir de los datos de expresión génica, la farmacogenómica siempre ha tenido una gran componente estructural. La estructura en 3D de las drogas puede ser crítica para comprender los mecanismos de acción y para la construcción de farmacóforos para el diseńo de las drogas antitumorales (24). El creciente número de estructuras proteicas en 3D en las bases de datos, sobre 15000 en la actualidad, permite crear mediante diferentes herramientas de software modelos de interacciones entre proteinas y sus ligandos. Así por ejemplo se ha avanzado en los algoritmos de anclaje molecular combinando propiedades geométricas y energéticas con el propósito de entender como interaccionan las superficies de la proteina diana y la molécula de la droga antitumoral. Un proyecto de gran relevancia que persigue la integración de las distintas areas de conocimiento en farmacogenómica es el PharmGKB (http://pharmgkb.org/). Este proyecto ha sido coordinado por la Universidad de Stanford dentro del programa de cooperación en investigación del NIH. Se trata de una base de datos que será el repositorio central de los datos farmacogenómicos (genómicos, moleculares, celulares y clínicos) obtenidos de múltiples instituciones médicas. El esfuerzo inicial de éste proyecto se centra en la construcción de representaciones y estándares XML para afrontar la heterogeneidad de los datos genómicos, de cinética enzimática y clínicos. El propósito es servir de soporte a la comunidad científica para la comprensión de cómo las variaciones genéticas contribuyen a las diferentes respuestas a tratamientos. Para concluir, mencionar que la farmacogenómica precisa cambios en el método con el que se están realizando los ensayos clínicos con fármacos antitumorales. El ejemplo del desarrollo de STI571 para tratamiento de la leucemia mielode crónica, ofrece claves sobre las características de estos nuevos ensayos. Sin embargo el desarrollo de los fármacos contra dianas específicas se enfrenta en la actualidad a dificultades (25). Los principales son el escaso número de agentes que alcanzan la fase clínica, el escaso número de enfermos que participan en protocolos de investigación clínica, el largo periodo de estudio, nuevos criterios de elegibilidad basados en la presencia de la diana específica en los tumores, la reducción de la población candidata al nuevo fármaco y el posible menor interés de la industria en fármacos de uso limitado. La raiz de estos problemas radica en que la integración de las ciencias computacionales y tecnologías de la información para el desarrollo de la investigación básica ha ocurrido antes que en el ámbito clínico. En un futuro próximo a medida que se generalizen las herramientas de la informática biomédica en el uso clínico diario se dará solución a la mayoría de estos problemas. Las nuevas plataformas en red harán factible el reclutamiento de un mayor número de pacientes en un menor tiempo y las nuevas técnicas experimentales de análisis molecular estarán accesibles en la práctica clínica rutinaria.
VI. Epidemiología del cancer La epidemiología del cáncer estudia los patrones de cáncer en las poblaciones y sus causas. Su objetivo es descubrir los factores genéticos, ambientales y de hábitos de vida así como las interacciones entre ellos. A través de estudios epidemiológicos, conocemos como cambian los patrones de incidencia de cáncer y de mortalidad en las poblaciones, los factores de riesgo para cánceres específicos, las potenciales estrategias de prevención y el papel de la variación genética en la etiología del cáncer. En la actualidad los estudios de epidemiología del cáncer son multidiciplinarios. Gracias a la reciente incorporación de las tecnologías computacionales tales como la bioinformática, conexiones entre múltiples bases de datos, modelos geográficos, y modelos de reconstrucción de exposición ambientales se pueden llevar a cabo estudios para la identificación de genes de susceptibilidad para un determinado cáncer y estimar la interacción entre genes y exposiciones ambientales en la etiología del cáncer. A modo de ejemplo, describimos un estudio de epidemiología genética en cáncer de pulmón orientado a la identificación de familias con alto riesgo (26). Parten de la hipótesis de que existe un genotipo específico que aumenta el riesgo de desarrollo de cáncer de pulmón con la exposición al humo del tabaco y otras exposiciones ambientales. Los datos hasta la fecha sugieren que existen componentes de susceptibilidad en cáncer de pulmón y que las interacciones entre los genes y el ambiente son importantes. El estudio se puede resumir en tres fases y cada una de ella se sustenta sobre una elaborada infraestructura de herramientas informáticas Se crea un registro informatizado de familias con alto riesgo para la realización de estudios sobre ligamiento genético en cáncer de pulmón. Para ello 11 instituciones identificarán e incluirán aquellas familias con al menos 3 familiares de primer grado con cáncer de pulmón. Se hará un screening de 70000 nuevos casos para identificar unas 800 familias con alto riesgo. Tras consentimiento informado se escogerán 100 familias para realizar los estudios de ligamientos genético y se recogerá, procesará y almacenará los datos de las muestras biológicas, clínico patológicas, demográficas, factores de riesgo y antecedentes familiares. Basado en los antecedentes familiares, los factores de riesgo y los datos genotípicos se realizarán análisis de ligamiento genético para identificar los loci de susceptibilidad. Una vez localizados y confirmados los loci de susceptibilidad, se identificará y caracterizará los genes de susceptibilidad mediante herramientas de bioinformática. El objetivo final es caracterizar dichos genes y desarrollar medios para la identificación de individuos y familias con alto riesgo y elucidar una estrategia para prevención, control y tratamiento de la enfermedad. El CGERB (Clinical and Genetic Epidemiology Research Branch) es la rama del programa del NCI que realiza investigación clínica y epidemiológica sobre el papel de los factores genéticos y sus interacciones en la susceptibilidad o la resistencia de los individuos y poblaciones al cáncer. Las principales áreas de investigación epidemiológica son la genética, interacciones gen-gen y gen-modificadores, caracterización de los genes de susceptibilidad a cáncer, sistemas de redes con información genética y clínica como los registros de familias, genética clínica de poblaciones, factores de progresión y pronóstico y estrategias de prevención y diagnóstico clínico. La infraestructura del CGERB cuenta con el Cancer Genetics Network (CGN) (http://epi.grants.cancer.gov/CGN/). Se trata de una red nacional formado por 8 centros especializados en el estudio de la predisposición genética a cáncer y un grupo de tecnología que proporciona el soporte e infraestructura informática. Realizan estudios cooperativos sobre las bases genéticas de susceptibilidad a cáncer, los mecanismos de integración de estos nuevos conocimientos en la práctica médica y los medios para satisfacer los asuntos psicosociales, éticos, legales y de salud pública. Cuenta con dos importantes registros familiares, el registro de cáncer de mama y ovario y el registro de cáncer de colon, que contienen información y muestras de más de 6000 familias con historia de cáncer. Una vez identificados y confirmados los factores de riesgo y susceptibilidad genética es precisa la utilización de herramientas software para poder ofrecer una estimación precisa e individualizada del riesgo/beneficio de posibles estrategias preventivas. El tratamiento quimioprofiláctico y la cirugía profiláctica son intervenciones efectivas para reducir la incidencia de determinados tumores como el cáncer de mama. Estas estrategias sin embargo comportan un coste y riesgo intrínseco. Por ello es esencial estimar de forma precisa e individualizada el riesgo de padecer un cáncer para poder obtener un análisis riesgo/beneficio previo a implementar las medidas de prevención. En la actualidad se está evaluando con éxito el impacto de sistemas informáticos de valoración de riesgo y consejo. En la última década se han propuesto diferentes modelos matemáticos para estimar el riesgo de cáncer de mama. El más extendido es el modelo Gail. Otros modelos son el Claus y BRCAPRO. Cada uno de estos modelos tiene unas ventajas y unas limitaciones. BRCAPRO por ejemplo calcula las posibilidades de padecer un cáncer de mama basado en la probabilidad de que una familia sea portadora de una mutación en uno de los genes de BRCA. Como ventaja ofrece un tratamiento muy minucioso de la información de los antecedentes familiares, sin embargo descuida factores de riesgo no familiares (27). Un estudio realizado por la Universidad de Texas (28) de 213 mujeres que acudieron a una clínica especializada de valoración de riesgo compara diferentes modelos matemáticos ejecutados con una herramienta de software llamada CancerGene y concluye que el modelo de Gail es una herramienta apropiada de estimación de riesgo aplicable en la mayoría de mujeres. En conclusión la nueva epidemiología en cáncer persigue traducir los avances sobre susceptibilidad genética en intervenciones efectivas a nivel de individuos y poblaciones y, para ello, debe desarrollar herramientas basadas en las ciencias de la computación y las nuevas tecnologías de análisis genético.
VII. Informática clínica en oncología
Acceso a la información sobre Cáncer La información en Internet no siempre es fiable y en ocasiones genera confusión. Los pacientes y familiares no siempre pueden distinguir aquella información que cumple con los estándares de la medicina actual de entre la información falsa o incompleta. Por dicho motivo están desarrollándose aplicaciones informáticas para identificar indicadores de precisión y veracidad de la información sobre salud disponible en Internet destinada a pacientes y público en general (29). Los sistemas computerizados de educación de los pacientes suponen una estrategia efectiva para la transferencia de conocimiento y desarrollo de habilidades. El empleo de dichos sistemas repercute en el beneficio de la salud de los pacientes (30). La telemedicina y las nuevas tecnologías ofrecen soluciones para mejorar la calidad de vida domiciliaria de pacientes crónicos. Para ello es necesario conocer sus necesidades. Con este fin se han realizado análisis de los requerimientos informáticos para la atención domiciliaria de pacientes oncológicos. Los pacientes deben de ser una parte principal en el proceso de desarrollo de sistemas online y en el diseńo de las interfaces (31). También existen múltiples portales y páginas en Internet con información para profesionales de la Oncología. PDQ (Physician Data Query) es una base de datos del NCI que contiene revisiones sistemáticas sobre tratamiento del cáncer, screening, prevención, genética y cuidados paliativos basado en revisiones de la literatura y opiniones de expertos; un registro extenso de ensayos clínicos y directorios de médicos y profesionales especializados en el tratamiento del cáncer. Destina una parte específica a los avances de la genética del cáncer en la prevención, screening y tratamiento del cáncer (http://cancernet.nci.nih.gov/genetics_prevention.html). Cancerlit (http://www.cancer.gov/search/cancer_literature/) es un recurso integrado de citas bibliográficas sobre las publicaciones en investigación sobre cáncer. Contiene más de 1.5 millones de citaciones desde 1963 hasta la actualidad, de más de 4000 diferentes fuentes. En 1998 se inició una reforma de CancerNet. Un grupo interdisciplinario se reunió para decidir las funcionalidades sobre el rango de los contenidos, la facilidad de navegación, diseńo de interfaces, empleo de nuevas tecnologías y accesibilidad. El objetivo fue desarrollar un sistema más robusto y flexible que pudiera acomodar actualizaciones a tiempo real, datos multimedia, y proporcionara avanzadas herramientas de búsqueda. Se diseńó una infraestructura flexible y escalable para soportar un sistema de información modular y dinámico. Para ello se desarrolló una base de datos universal (UDB) como repositorio y como herramienta de recuperación de información. Además contenía punteros a datos localizados en otras bases de datos de Internet. Se desarrolló un nuevo interfaz de usuario de CancerNet. Se está trabajando en el desarrollo de una aplicación de protocolo basado en la Web para protocolos de ensayos clínicos online, herramientas de software inteligentes que permitan adaptar las búsquedas a las necesidades del usuario y de descarga de información para asistentes personales de mano sin hilos. La UDB permite indexar más de 480 sumarios de información PDQ como documentos independientes con identificadores únicos de forma que pueda compilar respuestas específicamente ajustadas a las necesidades del usuario. Ello permite servir a audiencias altamente especializadas con información sobre cánceres específicos e importar sumarios de ensayos y estudios de fuentes acreditadas para su distribución en CancerNet. Esta nueva infraestructura está integrada con los sistemas de ensayos clínicos del NCI, proporcionando acceso seguro a los sistemas para envío electrónico, revisión, manipulación y actualización de los datos de los ensayos clínicos.
Relación medico-paciente Internet está cambiando la relación médico paciente. Entre otros servicios proporciona acceso a información sobre salud, consejos médicos online, sistemas de monitorización a domicilio y grupos de soporte online. Hace posible que el paciente asuma una mayor responsabilidad en su propia salud. Con ello, sin embargo, los pacientes pueden desafiar el papel tradicional del médico. Internet está incentivando a los pacientes a preguntar sobre la calidad de la información recibida. El uso de las nuevas tecnologías en la relación médico paciente está aumentando y tiene una mayor difusión en países anglosajones. En América estiman (32) que 52 millones de personas han utilizado Internet para buscar información sobre enfermedades, tratamiento médico y la disponibilidad de ensayos clínicos. Un 9% de estas personas han intercambiado e-mails con los médicos. América’s doctor (http://www.americasdoctor.com/) tiene contratos con 142 médicos que proporcionan consejos online sobre salud. WebMD (http://www.webmd.com/) proporciona grupos de discusión online con expertos médicos en varias materias. En 1999 estos servicios online alcanzaban una media de 3000 visitas por día. Las aplicaciones no están diseńadas para reemplazar a los facultativos en la toma de decisiones, sin embargo algunos médicos son escépticos (33). Las principales razones para no utilizar Internet de forma más activa en el manejo de los pacientes son la falta de remuneración, el incremento de tiempo necesario y la falta de credibilidad en la efectividad de los sistemas (34). Los estudios realizados hasta la fecha obtienen resultados positivos. Gustafson et al (35) ha realizado un estudio randomizado donde evalúa el impacto de un sistema de soporte a la decisión (CHESS) sobre calidad de vida de las mujeres jóvenes con cáncer de mama. El grupo experimental recibía un sistema domiciliario que proporcionaba información, ayuda para la toma de decisiones y soporte emocional. Concluían que los CDSS (Clinical decision support systems) tales como CHESS beneficiaban a los pacientes proporcionándoles una mayor competencia de información, soporte emocional y una participación más activa en su enfermedad. Los beneficios eran mayores para las poblaciones marginadas. La adopción de las nuevas tecnologías es lenta y las nuevas aplicaciones deben ser fáciles de usar y deben adecuarse a las necesidades de los facultativos con un índice beneficio-coste positivo tanto para las instituciones sanitarias como para los médicos. Los médicos pueden ayudar a los pacientes a encontrar e interpretar de forma fiable información actualizada. Con ello pueden hacer la relación médico-paciente más productiva. El convencer a los médicos para que tomen las riendas en la construcción de nuevas relaciones con sus pacientes mediante el uso de las nuevas tecnología es un reto para la comunidad médica (36).
Integración de la información genética y molecular en la historia clínica oncológica informatizada El mayor conocimiento del genoma humano está motivando una redefinición de las enfermedades con una clasificación genotípica más que fenotípica. Se postula que en un futuro no muy lejano el clínico deberá trabajar con matrices de decisión sobre el mejor tratamiento en las que tendrá que contemplar las variaciones genéticas individuales y los subtipos de enfermedad. La incorporación de la información genética en la práctica clínica llevará consigo la generación de una historia clínica genética y la aparición de nuevos protocolos y herramientas de apoyo a la toma de decisiones clínicas. Al mismo tiempo las historias clínicas electrónicas almacenadas en bases de datos locales se vincularán a multiplataformas en red de acceso integrado a las bases de datos remotas con información genética y clínica, y proporcionarán el acceso al software necesario para el análisis de dicha información, mediante herramientas de soporte de decisión y guías de práctica clínica (37). Gracias a estos sistemas se acelerará y facilitará el descubrimiento de marcadores genéticos de diagnóstico, pronóstico y respuesta a tratamiento oncológico y se facilitarán los estudios epidemiológicos moleculares en cáncer. El proyecto europeo INFOGENMED (38) está desarrollando un sistema multiplataforma de acceso unificado a bases de datos heterogéneas clínicas y genéticas. Se distinguen tres niveles de flujo de información: en un primer nivel la información genética de los pacientes, obtenida a partir de biochips y otros tests genéticos, se integrará en una base de datos local; en el segundo nivel, mediante la aplicación ARMEDA, se proveerá acceso unificado a bases de datos heterogeneas remotas con información clínica y genética así como las herramientas de software para la gestión de la información; en un tercer nivel se incorporarán al sistema protocolos y herramientas de soporte a la decisión para su uso en la práctica clínica. Este sistema proporcionará la infraestructura para estudios cooperativos entre investigadores clínicos y geneticistas, vinculando la información de repositorios locales de datos clínicos y genéticos en una base de datos virtual. En la elaboración de dichos sistemas es fundamental la captura adecuada de los conceptos. La informática médica ha trabajado en el campo de la terminología médica desde hace varias décadas. Sin embargo el conocimiento genético aplicado a la práctica clínica genera nuevos conceptos y ontologías. Un proyecto de la Clínica Mayo (39) está dirigido a examinar la cobertura de los principales sistemas de codificación aplicado a los conceptos presentados en los eventos adversos a terapia génica. Pretende determinar si alguno de los sistemas puede acomodar las variaciones de expresión de los conceptos presentes en los informes de efectos adversos a terapia génica y analizar la estructura semántica del contenido utilizando un sistema de lenguaje médico unificado, "Unified Medical Language System" (UMLS). Sistemas de soporte a la toma de decisiónes en la práctica oncológica El uso de los CDSS facilita la práctica de la medicina basada en la evidencia y promete mejorar de forma sustancial la calidad de la práctica médica. Hunt DL et al (40) en 1998 realizaron una revisión sistemática sobre los efectos de los sistemas de soporte a la decisión en el rendimiento de los médicos y las consecuencias sobre pacientes. Para ello seleccionaron 40 estudios desde 1992 a 1998 que evaluaban sistemas CDSS y los comparaban a un grupo control. Concluyeron que tanto el número como la calidad ha aumentado con los ańos, que los CDDS mejoraron el rendimiento médico para la dosificación de tratamientos, las medidas preventivas y otros aspectos, pero en aquella fecha aún no demostraron un aumento de la eficiencia en los diagnósticos. En la actualidad se están desarrollando múltiples CDSS en Oncología y su rendimiento está siendo evaluado. El equipo de Bouaud J et al. (41) llevó a cabo un estudio de evaluación de OncoDoc, un CDSS aplicado para cáncer de mama. En total se analizaron 127 decisiones. El cumplimiento de los facultativos con los criterios de la mejor práctica aumentó a un 85% (p<0.001), tras la utilización del sistema. La comparación entre las decisiones antes y después, mostró una modificación de las decisiones en un 31% de los casos. La tasa de reclutamiento en ensayos clínicos se incrementó en un 50%. En otro trabajo Hudson et al (42) describe un sistema de razonamiento para un sistema de soporte a la decisión de tratamiento con quimioterapia en cáncer. Se trata de un sistema escalable de forma que se pueda incorporar nueva información, en particular datos sobre genómica y nuevos fármacos. Se basa en una estructura de conocimiento que además de evaluar las condiciones, incorpora un razonamiento de anticipación de consecuencias. Se prevé que la aplicación de los CDSS en Oncología mejoren la eficiencia en la toma de decisiones en múltiples entornos tales como consultas externas y hospitalización. La generalización de su uso abastecerá a los repositorios con información clave para la medicina basada en la evidencia y harán posible la identificación y la respuesta a múltiples cuestiones epidemiológicas (43). En general aún queda mucho por hacer para alcanzar los potenciales beneficios de los CDSS. Un trabajo recientemente publicado en JAMIA elabora una serie de recomendaciones para mejorar el desarrollo de los CDSS y acelerar su adopción en las siguientes áreas: metodología y aspectos técnicos; captura de conocimiento interpetable por la máquina a partir de la literatura científica y de la medicina basada en la evidencia; evaluación del rendimiento y los costes; y política de incentivación para la adopción de los CDSS por las instituciones sanitarias. Se están realizando diversos trabajos para optimizar las estrategias de búsqueda, que ayudan a buscar información en Internet y en bases de datos como Medline de forma más eficiente, encontrando las respuestas a las cuestiones de los usuarios de forma más rápida y concisa. Estos sistemas están siendo evaluados positivamente en grupos de pacientes oncológicos y familiares (44) así como en facultativos (45). En la actualidad existe suficiente evidencia de que la informatización de la medicina mejora la sanidad y disminuye el error médico. En un relevante estudio (46) se presentan estadísticas sorprendentes sobre el error médico. Se estima que del 53% a 89% de los eventos adversos a drogas son identificables y que una pequeńa parte, pero significativa en números absolutos, puede ser prevenida mediante herramientas de software basados en algoritmos de análisis de características de pacientes, prescripción y dosificación de drogas. También se estima que los sistemas de soporte a la decisión pueden recortar los eventos adversos a drogas en un 55%, que además supone un ahorro sobre $4000 por evento. El IOM concluye que un sistema computerizado que cueste de $1 a 2 millones se amortizaría en 3 a 5 ańos, a la vez que prevendría dańos a cientos de pacientes. Un meta análisis publicado en 1996 por Shea S (47) de 16 estudios randomizados que evaluaban la efectividad global de los sistemas computerizados de alerta al nivel de ambulatorio dirigido a prevención de enfermedades, mostraron una mejora en la práctica de screening para cáncer de mama (OR 1.88; 95% CI 1.44-2.45) y cáncer colorectal. Concluyeron que la evidencia de estudios controlados randomizados demuestra la efectividad de los sistemas de alerta para los servicios de prevención en el nivel de ambulatorios. Las necesidades de información no reconocidas por el médico pueden ocurrir cuando hay información disponible sobre nuevos avances que pueden repercutir potencialmente en el manejo de los pacientes, pero debido a la sobrecarga de datos y el poco tiempo disponible ha pasado desapercibido para el facultativo. El grupo de Wanda Pratt está explorando sistemas de identificación de patrones en las historias clínicas electrónicas que guíen la elaboración automática de consultas en las bases de datos médicas y otras fuentes en Internet para filtrar y extraer información relevante para la actualización del médico en las áreas que conciernen a sus pacientes. Aplicaciones informáticas para protocolos de ensayos clínicos y guías de práctica clínica. Los protocolos y guias de práctica clínica son utilizados en diversas áreas incluyendo ensayos clínicos, sistemas de soporte a la decisión, referencias, desarrollo de políticas, educación sanitaria, y para facilitar flujos de trabajo. Existe una tendencia hacia la reducción de los costes y la variabilidad en la práctica clínica mediante el uso de guías de práctica clínica a través de herramientas de soporte de decisión para ayudar a los clínicos a seguir las recomendaciones de los protocolos. La representación y el procesamiento de guidelines complejas es un reto para la informática biomédica. Actualmente la investigación en cáncer se enfrenta a muchos problemas. Tanto pacientes como oncólogos deben realizar un tremendo trabajo administrativo basado en papel. Los ensayos clínicos producen datos eclécticos no centrados en la historia clínica del paciente sino en las especificaciones de los protocolos de ensayo, con duplicidad y redundancia de datos. La historia clínica del paciente está mayoritariamente en formato papel y se maneja manualmente. No existe un método sistemático para llevar los descubrimientos a la práctica clínica habitual y no existe una infraestructura que de soporte de forma global a los ensayos clínicos y la investigación básica. Los recientes avances en las tecnologías de la información y el explosivo crecimiento de Internet significan una gran oportunidad para alcanzar los siguientes objetivos: La integración de la información básica y clínica en cáncer, desde los fundamentos moleculares hasta la situación clínico-patológica del paciente oncológico La agilización de los ensayos clínicos, asistiendo al desarrollo de protocolos y reduciendo de forma significativa el tiempo desde el descubrimiento hasta los ensayos clínicos El desarrollo de estándares utilizables por el sector público y privado que aseguren interoperabilidad La provisión de información segura adecuada a las necesidades de los usuarios, satisfaciendo los requerimientos de los ensayistas, pacientes, oncólogos, compańías aseguradoras y demás personal autorizado. La informatización reporta ventajas a lo largo de todo el ciclo de vida de los ensayos clínicos. Desde el desarrollo del protocolo, el reclutamiento de los pacientes, el screening, la implementación del protocolo, hasta los análisis y la publicación de los resultados. Permiten la interconexión entre los sistemas de información hospitalarios que contienen la información clínica y los protocolos de investigación. Permite la representación y visualización de datos médicos complejos. La recogida de datos se realiza en tiempo real desde lugares emplazados en diferentes partes del mundo y puede ser la mejor solución para ensayos clínicos multicéntricos que requieren grandes tamańos muestrales. La calidad de los datos puede ser verificada al tiempo de la entrada mediante filtros y reglas de validación. La validación puede consistir en algoritmos simples que alerten al usuario de la presencia de ciertas condiciones. Un ejemplo es la aplicación del NCI Common Toxicity Criteria; el software ayuda al usuario a informar sobre un posible efecto adverso a droga basado en incrementos de los valores de laboratorio. Cuando el usuario no puede dar respuesta inmediata a dichas consultas dirigidas por el ordenador, entonces éstas pueden ser archivadas y ser respondidas a posteriori. Existen muchos tipos de validaciones: detección de ausencia de datos, detección de posibles artefactos (fuera de los rangos posibles), datos contradictorios entre sí; cambios de patrones de datos en el tiempo (48). Las validaciones cruzadas permiten además comparaciones entre datos: por ejemplo entre las medidas de las lesiones de una visita a otra. La captura directa de la información desde los sistemas de información clínica a los protocolos de los ensayos clínicos permite una reducción de los errores de transcripción de datos. Existen muchas iniciativas de desarrollo de guías de práctica clínica (GPCs) informatizadas, con mucha redundancia y solapamiento entre los productos resultantes, pero existe muy poca estandarización que facilite su uso de forma compartida o posibilite su adaptación a usos locales. En respuesta a estas necesidades GLIF.ORG (http://www.glif.org), un proyecto de la Universidad de Harvard en colaboración con otras instituciones académicas, está trabajando en la representación estructurada de las GPCs para facilitar su uso de forma compartida. El objetivo es proporcionar una representación para GPCs con las siguientes funcionalidades: Independencia del tipo de plataforma informática para lograr su uso de forma compartida y capacidad de integración de sistemas de información clínicos heterogéneos. Soporte para diferentes tipos de CPGs. Adaptabilidad a diferentes usos tales como sistemas de soporte a la decisión para pacientes y médicos, sistemas de control de calidad, de educación médica y de pacientes. Adaptabilidad a diferentes entornos locales con unas características concretas según los diferentes sistemas de salud, los patrones de enfermedad, los recursos de equipamiento y de tratamiento, así como diferentes entornos ya sean hospitalarios o ambulatorios, rurales o urbanos. El uso de los CPGs de práctica estándar y los protocolos no conllevarán a una mejora de la práctica clínica oncológica y a una reducción de los costes si los sistemas de información no pueden proporcionar un consejo al diferente personal adaptado a las características específicas de cada entorno y situación. La automatización de los guidelines de tratamiento utilizando situaciones simplificadas – reglas de acción o transición de diagramas según estado- no pueden captar los matices de cada situación clínica y son difíciles de mantener con el tiempo. Escalables y ampliables para facilitar su actualización periódica. Capacidad de procesamiento de información para la abstracción de los detalles en conceptos de alto nivel de complejidad. La FDA (49) ha adoptado unos protocolos para los sistemas computerizados de ensayos clínicos que suministran datos a este organismo. En particular los sistemas deben constar de procedimientos establecidos para la estructuración del sistema, mantenimiento del sistema, recolección de datos, archivo y recuperación de datos, y de seguridad de los datos. Esto incluye el empleo de las firmas digitales y acceso restringido según usuarios. La necesidad de integrar información molecular con los datos clínicos implica que la información sobre genotipos es distribuida por Internet. Es crucial que se mantenga la privacidad y la seguridad de los datos de los pacientes. En ciertas ocasiones el simple método de eliminar los datos identificativos como nombre, dirección y otra información demográfica no es suficiente. Existen en la actualidad otros métodos más avanzados para asegurar la privacidad del paciente (50-52). Uno de los retos principales de la informática biomédica es la creación de estructuras de datos que almacenen la información de una forma adecuada para su procesamiento por los programas de ordenadores. Hay una diferencia entre el formato de datos útil para los lectores (revistas, tablas y figuras) y aquellas que son útiles para ordenadores (estructuras de datos que codifican todos los datos para su recuperación y análisis). Los tipos de datos que deben ser representados son diversos – datos genómicos, moleculares, celulares y clínicos y poblacionales. También son diversos los tipos de conexiones para el intercambio de datos. Hasta la fecha se ha avanzado mucho en la creación de vocabularios (ICD-CM, LOINC, SNOMED, UMLS) pero no son estándares establecidos y tanto los médicos, como los investigadores y educadores generalmente no son capaces de utilizarlos siguiendo la forma natural de utilización del lenguaje. Se está trabajando en la estandarización de la terminología y su vinculación con otra terminología médica. El NCI están trabajando en la creación de un único vocabulario de términos clínicos, clasificaciones y nomenclaturas. Existen en la actualidad diferentes iniciativas académicas que proporcionan herramientas para el desarrollo de CPGs informatizados. Algunas de las más importantes se recogen en la Tabla II. Tabla II. Iniciativas académicas que proporcionan herramientas para el desarrollo de CPGs informatizados
Existen varias redes de distribución de protocolos electrónicos vía Web. Physicians Research Network (53) fue evaluado en varios centros oncológicos americanos. La red consistía en 147 protocolos. Demostró ser una forma fiable y segura de distribución de protocolos, de reducción de costes, errores y retrasos en la distribución. Se han desarrollado diferentes sistemas de soporte a la decisión para la elección de protocolos proporcionando una evaluación automatizada de los criterios de inclusión y exclusión en función de las características de los pacientes. CancertrialsHelp (http://www.cancertrialshelp.org/) es una agrupación de los grupos cooperativos de cancer americanos que ha licenciado direrentes modelos de aplicaciones para ensayos clínicos en oncolología. Uno de sus productos TrialCheck es un sistema de soporte a la decisión para la elección de protocolos de ensayos clínicos proporcionando sistemas informatizados de inclusión de los pacientes. También se han diseńado asistentes digitales personales de mano para dichos fines (54,55). En EE.UU., están trabajando en la aplicación de las nuevas tecnologías para dar soporte al NCI. En concreto, se ha impulsado la creación de una infraestructura informática para la aceleración de los ensayos clínicos y se pretende ampliarla a todo el abanico de investigación en cáncer tanto dentro como fuera del NCI (Fig. 3). Su objetivo es facilitar la transición de la investigación básica en la clínica. Dicha infraestructura incluye el desarrollo de estándares como por ejemplo los CDEs (elementos comunes de datos); la creación de repositorios de información de uso compartido, desarrollo de plantillas de ensayos clínicos y la elaboración de componentes para la construcción de ensayos clínicos. (56,57)
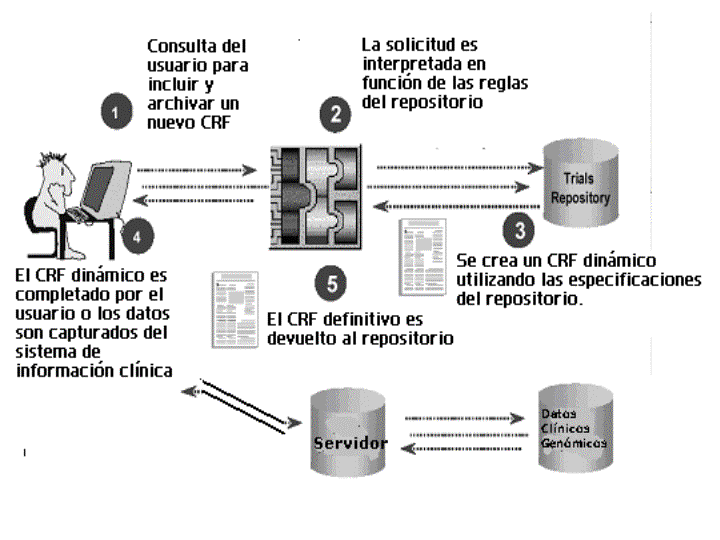
A modo de ejemplo en la Fig. 4 se observa un modelo simplificado del flujo de información para protocolos de ensayos informatizados.
El médico podrá completar un formulario electrónico sencillo, enviarlo mediante una conexión segura y si el paciente y la institución sanitaria cumplen con ciertos estándares o criterios, el paciente podrá ser incluido dentro del ensayo clínico. Las correcciones serían completadas en tiempo real, siguiendo las especificaciones enviadas por el repositorio y el CRF definitivo sería devuelto al repositorio de ensayos. En los casos en los que existiera un sistema informatizado de la historia de salud, los datos se capturarían durante el encuentro médico-paciente, seguido de la generación de CRFs definitivos a partir de los repositorios de datos clínicos. La información requerida específicamente por el ensayo clínico seria generada automáticamente desde los sistemas locales utilizados para la documentación de la atención médica rutinaria del paciente. A su vez, gracias a un reclutamiento más veloz y abierto a múltiples instituciones se dará respuesta a las cuestiones científicas de forma mucho más rápida.
REFERENCIAS 1.- Clark MS. 1999. Comparative genomics: the key to understanding the Human Genome Project. Bioessays 21: 121-30. 2.- Nadkarni PM, Marenco L, Chen R, Skoufos E, Shepherd G, Miller P. 1999. Organization of heterogeneous scientific data using the EAV/CR representation. J Am Med Inform Assoc 6: 478-93. 3.- Kallioniemi OP. Biochip technologies in cancer research. Ann Med. 33:142-7, 2001. 4.- Alizadeh, A. A. , Eisen, M. B. , Davis, R. E. , Ma, C. , Lossos, I. S. , Rosenwald, A. , Boldrick, J. C. , Sabet, H. , Tran, T. , Yu, X. , et al. (2000) Nature (London) 403, 503-511 5.- Davis E, Brown K, Siebenlist U, Staudt L. Constitutive Nuclear Factor B Activity Is Required for Survival of Activated B Cell–like Diffuse Large B Cell Lymphoma Cells R. J. Exp. Med. 2001 Dec. 17. 194 (12) 1861-1874. 6.- Sorlie T, Perou CM, et al. Gene expression patterns of breast carcinomas distinguish tumor subclasses with clinical implications. (2001). Proc Natl Acad Sci U S A 98(19):10869-74 7.- Garber M, Troyanskaya O, Schluens K, Petersen S, Thaesler Z, Pacyna-Gengelbach M et al. Diversity of gene expression in adenocarcinoma of the lung. Proc. Natl. Acad. Sci. USA, Vol. 98, Issue 24, 13784-13789, November 20, 2001 8.- Hedenfalk, I. , Duggan, D. , Chen, Y. , Radmacher, M. , Bittner, M. , Simon, R. , Meltzer, P. , Gusterson, B. , Esteller, M. , Kallioniemi, O. P. , et al. (2001) N. Engl. J. Med. 344, 539-548 9.- Golub, T. R. , Slonim, D. K., Tamayo, P. , Huard, C. , Gaasenbeek, M. , Mesirov, J. et al. (1999) Science 286, 531-537 10.-. Paweletz et al. Rapid protein display profiling of cancer progression directly from human tissue using a protein biochip. Drug Dev Res 2000; 49:34 11.- Chow M, Moler E, and Mian IS. Identifying marker genes in transcription profiling data using a mixture of feature relevance experts. Physiological Genomics 2001;5:99-111 12.- van 't Veer LJ, Dai H, van de Vijver MJ, et al. Gene expression profiling predicts clinical outcome of breast cancer. Nature 2002 Jan 31;415(6871):530-6. 13.- Amos AF, Kavanagh AM, Cawson J. Radiological review of interval cancers in an Australian mammographic screening programme. Radiology Quality Assurance Group of Breast Screen Victoria. J Med Screen. 2000;7:184-189 14.- Taft R, Taylor A. Potential Improvement in Breast Cancer Detection With a Novel Computer-Aided Detection System.. Appl Radiol 2001;30(12):25-28 15.- Underwood J, Tate AR, Luckin R, Majos C, Capdevila A, Howe F, Griffiths J, Arus C. A prototype decision support system for MR spectroscopy-assisted diagnosis of brain tumours. Medinfo 2001;10(Pt 1):561-5 16.- Weissleder R, Mahmood U. Molecular Imaging. Radiology 2001; 219:316–333 17.- Weissleder R. Scaling Down imaging: Molecular Mapping of Cancer in Mice. Review. Nature 2002; 2: 1-8 18.- Rehemtulla A, Hall D, Stegman L, Chen G, Bhojani MS, Chenevert T and Ross B. Molecular Imaging of Gene Expression and Efficacy Following Adenoviral-Mediated Brain Tumor Gene Therapy. Molecular Imaging 1, 43-55; 2002 19.-Novel Tyrosinase Mutants as Imaging Marker Genes. Grant Number: 1R21CA085657-01A1 PI Name: Bogdanov, Alexei Boston, MA 02114 20.- Murphy MP. 2000. Current pharmacogenomic approaches to clinical drug development. Pharmacogenomics 1: 115-23. 21.- Altman R, Klein T.Challenges for Biomedical Informatics and Pharmacogenomics. Stanford Medical Informatics.2001 22.- Scherf U, Ross D, Waltham M, Smith L, Lee J, Tanabe L. A Gene Expression Database for the Molecular Pharmacology of Cancer. Nature Genetics 24(3): 227-234, 2000 23.- Slonim DK. 2001. Transcriptional profiling in cancer: the path to clinical pharmacogenomics. Pharmacogenomics 2: 123-36. 24.- Ekins S, de Groot MJ, Jones JP. 2001. Pharmacophore and three-dimensional quantitative structure activity relationship methods for modeling cytochrome p450 active sites. Drug Metab Dispos 29: 936-44. 25.- Espańa Saz P. Revisión crítica sobre las nuevas dianas terapéuticas. Revisiones en Cáncer. 16(1): 37-38,2002 26.- Anderson M. Genetic Epidemiology of Lung Cancer I: Gene Identification in High-Risk Families. University of Cncinnati Department of Environmental Health, Ohio . 27.- Euhus DM, Leitch AM, Huth JF, Peters GN. Limitations of the Gail model in the specialized breast cancer risk assessment clinic. Breast J 2002 Jan-Feb; 8(1):23-7 28.- Euhus DM. Understanding mathematical models for breast cancer risk assessment and counseling. : Breast J 2001 Jul-Aug;7(4):224-32 29.- Fallis D, Frické M Indicators of Accuracy of Consumer Health Information on the Internet A Study of Indicators Relating to Information for Managing Fever in Children in the Home. Journal of the American Medical Informatics Association 2002; 9:73-79 30.- Lewis D. Computer-based Approaches to Patient Education A Review of the Literature. Journal of the American Medical Informatics Association 1999;6:272-282 31.- Tetzlaff L, Consumer Informatics in Chronic Illness Journal of the American Medical Informatics Association 1997; 4:285-300 32.- Web users search for medical advice most often. Wall Street Journal. Nov. 27, 2000:B14 33.- US General Accounting Office. Consumer health informatics: Emerging issues. Washington DC: US Government Printing Office; 1996. Publication No.T-AIMD-96-134. 34.- Anderson JG. How the Internet Is Transforming the Physician-Patient Relationship. Medscape TechMed 2001; 1(3) 35.- Gustafson DH, Hawkins R, Pingree S, McTavish F, Arora NK, Mendenhall J, et al Effect of computer support on younger women with breast cancer.. J Gen Intern Med 2001 Jul;16(7):435-45 36.- Shepperd S, Chatrnock D, Gann B Helping patients access high quality health information.. BMJ. 1999;319:764-766. 37.- Martín-Sanchez. F. López-Campos G. Ibarrola N. La Convergencia de la Informática Médica y la Bioinformática: Impactos en la práctica clínica y en la educación de los profesionales de la Salud. Unidad de Bioinformática- BIOTIC. Instuto de Salud Carlos III. http://biotic.isciii.es/guia_rec/publicacion/uimp.pdf 38.- V. Maojo , F. Martín-Sánchez , N. Ibarrola, G. H. et al. Functional definition of the INFOGENMED WORKSTATION: a virtual laboratory for genetic information management in clinical environments. Bioinformatics Unit. (BIOTIC). Institute of Health "Carlos III". Madrid, SPAIN. http://www.amia.org/pubs/symposia/D005863.PDF 39.- Gene Therapy Reports. A Content Coverage Study of Gene Therapy Adverse Events Reports. Mayo Clinic Division of Medical Informatics Research. NCI (contract) http://www.mayo.edu/research/mir/index.html 40.- Hunt DL, Haynes RB, Hanna SE, Smith K Effects of computer-based clinical decision support systems on physician performance and patient outcomes: a systematic review.. JAMA 1998 Oct 21;280(15):1339-46 41.- Bouaud J, Seroussi B, Antoine EC, Zelek L, Spielmann M. A before-after study using OncoDoc, a guideline-based decision support-system on breast cancer management: impact upon physician prescribing behaviour. Medinfo 2001;10:420-4 42.- Hudson DL, Cohen ME, Hudson SE. The use of consequential reasoning in cancer chemotherapy..Medinfo. 2001;10(Pt 2):1349-53. 43.- Sim I, Gorman P, Greenes R, Haynes B, Kaplan B, Lehmann, and Tang P. Clinical Decision Support Systems for the Practice of Evidence-based Medicine. Journal of the American Medical Informatics Association 2001;8:527-534 44.- Pratt W, Fagan, L The Usefulness of Dynamically Categorizing Search Results. JAMIA 2000; 7 (6): 1-11 45.-. Pratt W, Wasserman H. QueryCat: Automatic Categorization of MEDLINE Queries.. Proceedings of the American Medical Informatics Association (AMIA) Fall Symposium 2000. 46.- To Err is Human: Building a Safer Health System. Institute of Medicine. National Academy of Sciences. 1999 47.- Shea S, DuMouchel W, and Bahamonde L. A meta-analysis of 16 randomized controlled trials to evaluate computer- based clinical reminder systems for preventive care in the ambulatory setting. J. Am. Med. Inform. Assoc. 1996; 3: 399-409 48.- Spriet A, Dupen-Spriet T. Farmington, CT Good practice of clinical drug trials.: Karger, 1997. (2nd edition) pgn 67-70 49.- Food and Drug Administration. Guidance for industry, computerized systems used in clinical trials. April 1999. 50.- Wiederhold G, Bilello M, Sarathy V, Qian X A security mediator for health care information.. Proc AMIA Annu Fall Symp: 1996; 120-4. 51.- Sweeney L, Nolan PM Guaranteeing anonymity when sharing medical data, the Datafly System.. Proc AMIA Annu Fall Symp 1997; 1: 51-5. 52.- Malin B, Sweeney L. Determining the identifiability of DNA database entries.. Proc AMIA Symp. 2000: 537-41. 53.- Electronic Clinical Trial Protocol Distribution via the World-Wide Web. A Prototype for Reducing Costs and Errors, Improving Accrual, and Saving Trees Lawrence B. Afrin, MD, Valarmathi Kuppuswamy, BE, Barbara Slater, BS and Robert K. Stuart, MD http://www.amia.org/pubs/symposia/D200095.PDF 54.-Decisions at Hand: A Decision Support System on Handhelds. Blaz Zupan et al. MedInfo 2001; http://magix.fri.uni-lj.si/blaz/papers/MEDINFO-2001.pdf 55.- Pilot Study of a Point-of-use Decision Support Tool for Cancer Clinical Trials Eligibility Philip P. Breitfeld, et al. Indiana University School of Medicine, Indianapolis, Indiana. J. Am. Med. Inform. Assoc. 1999 6: 466-477. 56.- Silva J, Ball M, Douglas J. The Cancer Informatics Infrastructure (CII): An Architecture for Translating Clinical Research into Patient Care, IMIA 2001; 114-117 57.- Silva J, Wittes R. Role of Clinical Trials Informatics in the NCI’s Cancer Informatics Infrastructure, National Cancer Institute, Bethesda, Maryland. AMIA 1999 http://www.amia.org/pubs/symposia/D005403.PDF.
Informática y SaludNş 38. Noviembre 2002 |
|
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas] |
|
Copyright SEIS© 1997, 2002. |