INFORSALUD 2004
Madrid, 24-26 de marzo de 2004
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas]
|
INFORSALUD 2004 |
La Cooperación entre Redes Sanitarias |
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas] |
||
|
żCómo llegar a la sede del Congreso? Secretaría Técnica: CEFIC
|
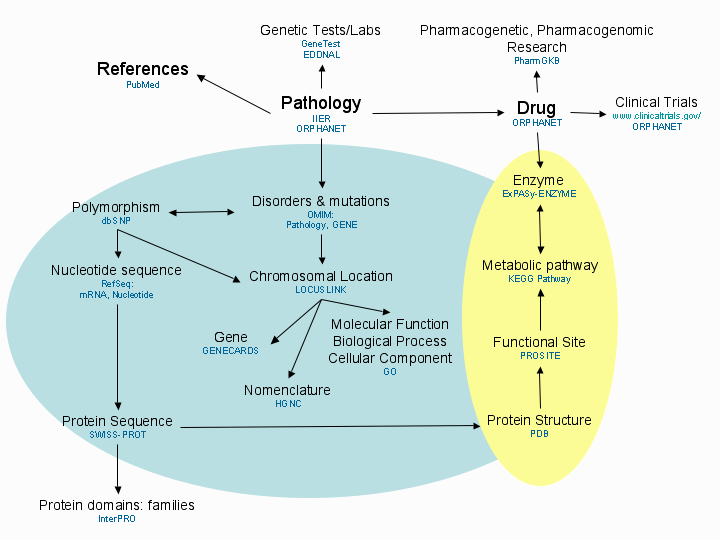
INFOGENMED: UN LABORATORIO VIRTUAL PARA LA INTEGRACIÓN DE INFORMACIÓN CLÍNICA Y GENÉTICA EN APLICACIONES MÉDICAS F. J. VICENTE1, I. HERMOSILLA1, M. GARCIA REMESAL2, D. PÉREZ DEL REY2, B. ROMERO2, I. OLIVEIRA3, J.L. OLIVEIRA3, A. SOUSA PEREIRA3, F. MARTIN-SANCHEZ1 1 2 Grupo de Informática Biomédica. Universidad Politécnica de Madrid. 3 IEETA. Universidad de Aveiro, Portugal. Un paciente acude al médico para realizar una consulta sobre una patología que tiene una prevalencia de cinco casos por cada diez mil personas, una enfermedad rara [8]. El clínico sabe que las causas de esta enfermedad son genéticas, pero no recuerda el nombre del gen que, al mutar, produce una proteína defectuosa. Tampoco conoce el nombre de la proteína ni los detalles de la vía metabólica que no funciona correctamente al estar disminuida la función enzimática de esa proteína. Toda esa información se halla disponible en Internet y en bases de datos locales de su hospital, sin embargo, el clínico no dispone del tiempo suficiente para navegar por las decenas de recursos de información genética existentes, que no están integrados y que además se han diseńado principalmente para ser empleados en un laboratorio de investigación biológica y no en una consulta clínica. En esta comunicación se describe cómo en el marco del proyecto europeo INFOGENMED se trata de facilitar este tipo de funcionalidades de acceso a información genética de interés para los clínicos haciendo uso de los métodos y técnicas de la Bioinformática Médica. 1. Introducción En septiembre de 2002, dio comienzo el proyecto europeo INFOGENMED (IST-2001-39013) (http://www.infogenmed.net) [1] que finalizará en agosto de 2004. Este proyecto está coordinado por el grupo IEETA de la Universidad de Aveiro, Portugal, y en él participan grupos de investigación y empresas lusas, suecas y espańolas. En concreto por parte espańola participan el Grupo de Informática Biomédica de la Universidad Politécnica de Madrid y el Área de Bioinformática del Instituto de Salud Carlos III. En este tiempo, se ha diseńado una herramienta que trata de dar respuesta a las inquietudes manifestadas en las entrevistas y cuestionarios cumplimentados por los usuarios finales (genetistas médicos, clínicos, investigadores), llevadas a cabo al principio del proyecto. El resumen de las mismas se centra en la necesidad de integrar las fuentes de información de naturaleza heterogénea, ampliamente distribuidas por la web, en un repositorio virtual que acceda a datos clínicos, genéticos y moleculares sobre una patología en un único entorno, fácilmente accesible por el usuario. Hasta la fecha, las bases de datos contabilizadas en la actualización anual de "The Molecular Biology Database Collection: 2004 update" [2] suman 548, categorizadas jerárquicamente. La especificidad de estos recursos y la especialización requerida para navegar por ellas hacen de estas colecciones herramientas solo accesibles a determinados colectivos muy experimentados, principalmente investigadores biológicos. Las bases de datos están elaboradas ad hoc, son heterogéneas, ofrecen diversos modos de acceso y a menudo emplean distintos sistemas para denominar a las mismas entidades (por ejemplo aliases de un gen, o diferentes identificadores de proteínas). Recuperar información relevante a partir de estas bases de datos para poder ser empleada en el entorno clínico requiere una serie de conocimientos y habilidades que INFOGENMED trata de proporcionar de un modo automático y transparente para el usuario. 2. Objetivos INFOGENMED se ha diseńado para ayudar al clínico a superar estos obstáculos, almacenando en un repositorio virtual la información de todas las bases de datos que integra este sistema. Hay que decir aquí que los ámbitos gestionados por el sistema inicialmente, son dos: -cáncer y -enfermedades genéticas raras. En el primer caso, el sistema tiene como objetivo integrar diversas bases de datos privadas provenientes del entorno clínico (datos de pacientes, patología, datos de laboratorio, prescripción de medicamentos, ...) con bases de datos de centros de investigación que recogen resultados de experimentos genómicos y proteómicos (secuencias, polimorfismos, expresión de genes obtenidos con microarrays, expresión de proteínas, ....). INFOGENMED proporciona un modelo virtual de datos en el que se pueden realizar estudios de correlación entre las características genéticas y moleculares de un tumor y la evolución clínica del mismo. En el entorno de las enfermedades raras, INFOGENMED debe facilitar la recuperación de información relevante sobre las bases moleculares de una patología, integrado terminologías, accediendo a recursos públicos a través de Internet y facilitando toda esa información al clínico sin que éste necesite conocer los códigos y nombres de las entidades genéticas subyacentes. Actualmente existen varios recursos dedicados a este área: el Instituto de Investigación de Enfermedades Raras del Instituto de Salud Carlos III (http://cisat.isciii.es/er/), ORPHANET, el portal francés de Enfermedades Raras (http://www.orpha.net/) y el sistema estadounidense NORD, que es una base de datos privada con la misma finalidad que las europeas y dependiente de la "Office of Rare Diseases" (http://rarediseases.info.nih.gov/) de naturaleza gubernamental. En ambos casos INFOGENMED se ha desarrollado para: integrar todas las fuentes biológicas, genéticas y clínicas relevantes mediante el empleo de un modelo conceptual y un protocolo físico, independientes de la arquitectura de la bases de datos y de la plataforma tecnológica que las sustenta. El modelo conceptual (representado en la figura 1) relaciona las entidades que pueden ser accedidas por el sistema mientras que el protocolo físico representa los procedimientos reales de navegación y recuperación de información entre las distintas bases de datos en función de las consultas que puede realizar el usuario (por ejemplo, el camino que se debe seguir desde la enfermedad hasta el laboratorio que realiza una prueba genética). Unificar los interfaces de usuario, simplificando la navegación. Hasta la fecha, el único modo de consultar las bases de datos recogidas en el modelo del protocolo conceptual es navegar por cada una de ellas por separado, con sus respectivos lenguajes de interrogación. El acceso a los aproximadamente 20 recursos se hará desde una sola pantalla del navegador y con un lenguaje de consulta único.
3. Métodos La arquitectura de INFOGENMED está representada en la figura 2 y se basa en los elementos funcionales que se describen a continuación:
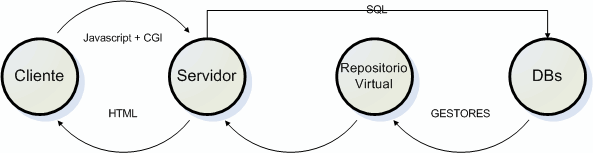
3.1. Servidor de vocabularios biomédicos. En el proyecto europeo BIOINFOMED (http://bioinfomed.isciii.es) [3] se identificaron 18 líneas que servían como una propuesta de Agenda de Investigación para la Informática Biomédica en los próximos ańos. La interoperabilidad de los estándares de comunicación y la integración de los recursos heterogéneos con técnicas de representación del conocimiento son dos de ellas. Para lograr este propósito se ha desarrollado un servidor de vocabularios que permite integrar en el sistema terminologías, tesauros y vocabularios biomédicos de utilidad para el proyecto. Algunos de los más importantes son UMLS [4, 5], GO (Gene Ontology), términos MeSH, o Human Gene Nomenclature. La funcionalidad de este módulo ha sido ya comprobada mediante el desarrollo de una utilidad que permite lanzar consultas al sistema utilizando términos MeSH en castellano. 3.2. ARMEDA. Constituye el verdadero "motor" de la aplicación, cuya primera versión se basa en el estándar de comunicación entre objetos CORBA (Common Object Request Broker Architecture) [6, 7] como puente de unión entre el usuario-servidor y entre servidor-bases de datos. En la actualidad se está desarrollando una segunda versión basada en el uso de agentes inteligentes. El usuario del sistema escribe su consulta (una patología, por ejemplo) a través de una interfaz, que se envía por Internet al servidor mediante una aplicación cliente-servidor desarrollada en javascript. El servidor genera una sentencia SQL (Structured Query Language) que se distribuye con los "gestores" de las bases de datos. Estos recopilan la información y la envían de nuevo a los usuarios en formato html creándose un repositorio virtual intermedio que recoge la información recuperada por los objetos "gestores". De este modo el usuario tiene la impresión de que está trabajando contra una única base de datos, aunque realmente ésta no exista sino que se cree mediante el mapeo de datos a las fuentes originales.
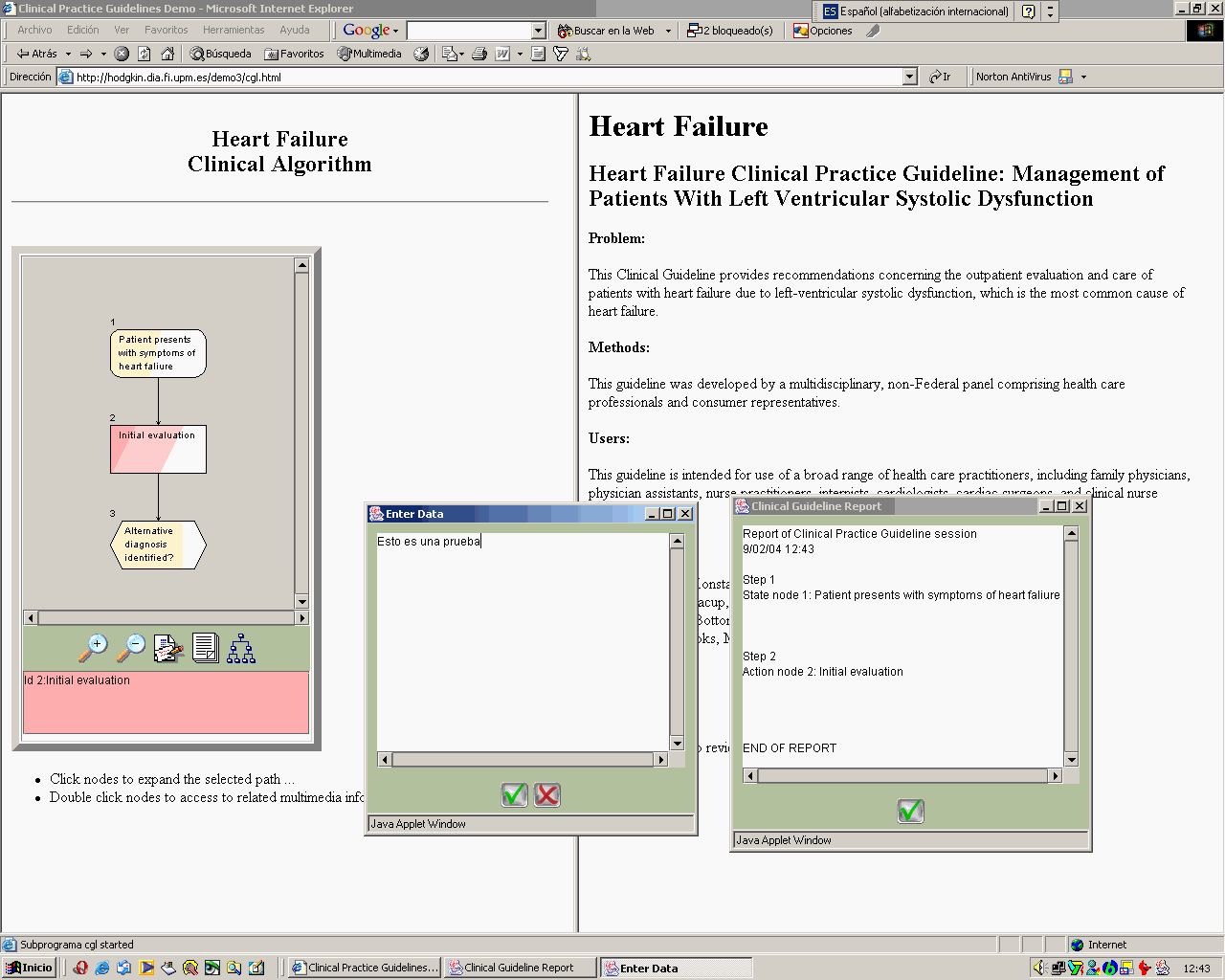
3.3. Asistente a la navegación Esta herramienta está pensada para dar soporte a la navegación del usuario final. Basada en un navegador de Internet, el sistema dividirá en ventanas la pantalla y en ellas se visualizarán las imágenes descritas a continuación.
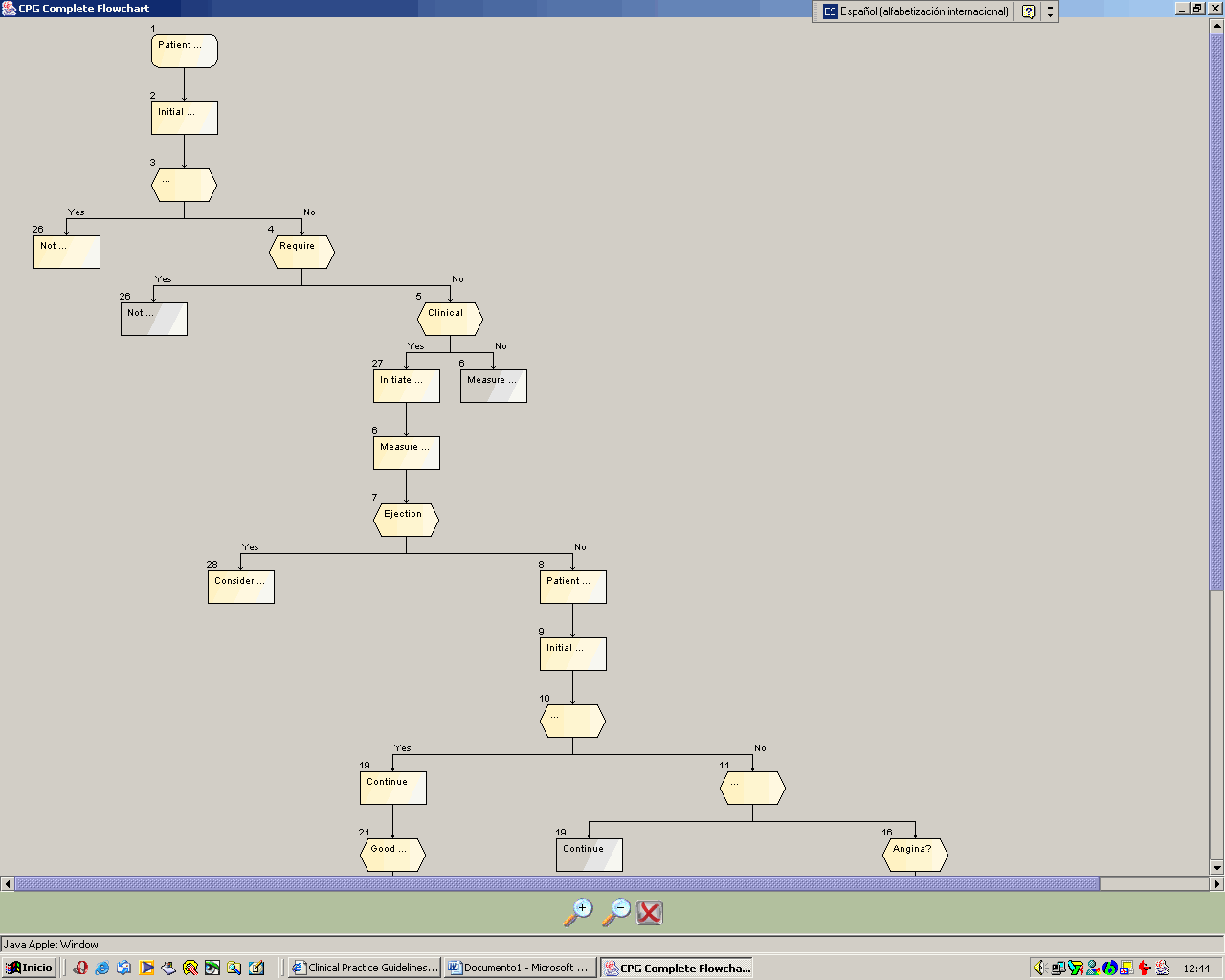
La figura 4 representa el aspecto que presenta esta utilidad para el usuario. En el marco izquierdo, aparece el diagrama de flujo con los pasos secuenciales a dar y una breve explicación de los mismos. En el marco de la derecha, aparecerá la página web de la base de datos a la que se esté realizando la consulta cuando se seleccione con el ratón en el diagrama de flujo. Dos applets permiten la entrada de datos por parte del usuario y la lectura y zoom sobre todo el protocolo para personalizar la navegación. Los nodos del diagrama de flujo, además de enlazar con páginas web y bases de datos, permiten la incorporación de contenidos multimedia, como videos o animaciones, lo que introduce un valor ańadido a la herramienta como elemento de formación. En la figura 5 se aprecia un diagrama con las ramas y las características de los nodos: un cuadrado de esquinas romas manifiesta estado; un cuadrado, acción y, un hexágono, una decisión.
Conclusiones INFOGENMED representa uno de los primeros intentos de integrar de modo efectivo y con una perspectiva médica las principales fuentes de datos genéticas y clínicas que se generan en los centros de investigación biomédica y los repositorios de información biológica públicos, accesibles libremente a través de Internet. El sistema trata de resolver algunos de los importantes problemas asociados a la heterogeneidad de estructuras y usos asociados a estos recursos, a los sistemas independientes de representación de conceptos biológicos y médicos (ontologías, terminologías) y a la compleja lógica de navegación que se necesita dominar para obtener la información relevante en tiempos aceptables. Agradecimientos Este trabajo ha sido financiado por el proyecto europeo INFOGENMED de la Comisión Europea, perteneciente al Programa IST (Information Society Technologies) (IST-2001-39013). Referencias [1] A. S. Pereira, V. Maojo, F. Martin-Sanchez, A. Babic e S. Goes (2002) "The Infogenmed Project" In Int. Congress on Biological and Medical Engineering, Singapure. [2] Galperin MY. The Molecular Biology Database Collection: 2004 update. Nucleic Acids Res. Jan 1;32 Database issue: D3-22. (2004) [3] Synergy between medical informatics and bioinformatics: facilitating genomic medicine for future health care. Fernando Martin-Sanchez et al. Journal of Biomedical Informatics, Noviembre 2003, (on line). [4] Siegel, J.: "CORBA Fundamentals and Programming", John Wiley & Sons, Inc., 1996. [5] Alamo, S.: "Armeda: Acceso Remoto a Bases de Datos Medicas a través de Internet". Proyecto de fin de carrera, Universidad Politécnica de Madrid, 1998. [6] Bodenreider O.: The Unified Medical Language System (UMLS): integrating biomedical terminology. Nucleic Acids Res. 2004 Jan 1;32 Database issue:D267-70. [7] Lindberg DA, Humphreys BL, McCray AT. The Unified Medical Language System. Methods Inf Med. 1993 Aug;32(4):281-91. [8] COMMISSION REGULATION (EC) No 847/2000, of 27 April 2000, Official Journal of the European Communities, publicado en L 103/5, 28.4.2000
|
|
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas] |
|
Copyright SEIS© 1997-2004. |