INFORSALUD 2004
Madrid, 24-26 de marzo de 2004
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripciµn SEIS] [Bºsquedas]
|
INFORSALUD 2004 |
La Cooperaciµn entre Redes Sanitarias |
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripciµn SEIS] [Bºsquedas] |
||
|
¢Cµmo llegar a la sede del Congreso? SecretarÚa TÕcnica: CEFIC
|
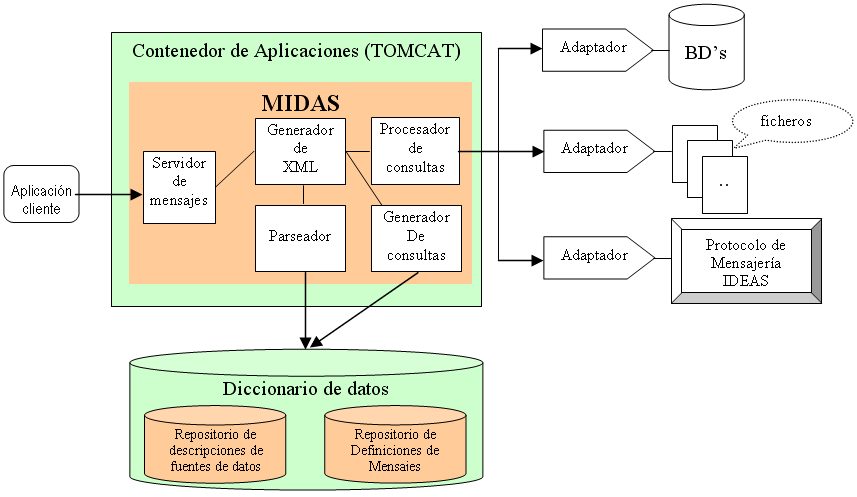
MIDAS: Un sistema para el acceso unificado a registros clÚnicos distribuidos. A. SANCHIS1, J.A. MALDONADO1, P. CRESPO1, M. ROBLES1, R. GARCIA2 , M.CORRECHER2 1 Grupo BET (BioingenierÚa, Electrµnica, Telemedicina e InformÃtica MÕdica) de la Universidad PolitÕcnica de Valencia. 46022-Valencia.2 Servicio de InformÃtica del Hospital La Fe de Valencia Resumen: En un entorno hospitalario como el del Hospital Universitario La Fe, los diferentes departamentos han incorporado las tecnologÚas de la informaciµn a sus procesos progresivamente, normalmente sin una polÚtica conjunta, y eligiendo los sistemas que se han considerado mÃs adecuados para satisfacer sus necesidades. Esto ha ocasionado que en la actualidad nos encontremos en una situaciµn donde conviven un conjunto heterogÕneo de sistemas de informaciµn, planteando cada uno de ellos, una problemÃtica diferente a la hora de acceder a su informaciµn. La necesidad de tener una vista unificada de la historia clÚnica electrµnica del paciente nos lleva, por tanto, ha desarrollar aplicaciones que han de hacer frente a esta heterogeneidad. El objetivo del proyecto MIDAS es crear la infraestructura necesaria para el acceso uniforme a las distintas fuentes de informaciµn clÚnica. 1. Introducciµn El proyecto MIDAS nace como colaboraciµn entre el grupo de informÃtica mÕdica del BET de la Universidad PolitÕcnica de Valencia y el Servicio de informÃtica del Hospital la Fe para intentar dar soluciµn a la demanda por parte del personal sanitario de una aplicaciµn que les permita tener acceso a una vista unificada de las historias clÚnica de los pacientes, para, de esta forma, agilizar algunos de los procesos que tienen los diferentes departamentos como el acceso a los resultados de las pruebas de laboratorios o al historial de pruebas radiolµgicas que se le han realizado a un determinado paciente. Se ha aprovecha la experiencia en el desarrollo de aplicaciones para el acceso y comparticiµn de informaciµn clÚnica basados en estÃndares que el grupo de sistemas de informaciµn hospitalarios ha adquirido con el proyecto PANGEA [1][2]. AsÚ, se han utilizado algunos de los conceptos utilizados en este proyecto y se han aplicado a MIDAS, sistema objeto de este artÚculo. 2. Integraciµn de datos Podemos entender por integraciµn de datos el problema de combinar datos que residen en diferentes sistemas, y proporcionar a los usuarios una vista unificada de Õstos. La integraciµn de datos ha sido y es un campo de investigaciµn muy activo, en la literatura informÃtica se pueden encontrar diversas arquitecturas y metodologÚas [3]. MIDAS, como sistema de integraciµn de datos, sigue una arquitectura basada en mediadores y adaptadores [4]. En esta arquitectura varias fuentes de datos estÃn "envueltas" por una capa de software, denominada adaptador o wrapper, el cual traduce entre el lenguaje, modelos y conceptos de la fuente de datos y el lenguaje, modelo y conceptos del mediador. Los mediadores obtienen la informaciµn a partir de una o mÃs fuentes de datos o de otros mediadores, es decir, de los componentes que estÃn por debajo de Õl, y proporcionan informaciµn a las componentes que estÃn por encima, en nuestro caso, los usuarios externos del sistema. Los sistemas de integraciµn basados en mediadores son utilizados cuando la necesidad de acceder a informaciµn actualizada y reciente es crÚtica o cuando es imposible o difÚcil el instanciar todos los datos almacenados en las fuentes. Esto es asÚ en el caso de la integraciµn de informaciµn clÚnica distribuida, el usuario final del sistema de integraciµn, por ejemplo el mÕdico que atiende al paciente, debe tener acceso a toda la informaciµn disponible del paciente hasta la fecha. La informaciµn clÚnica sobre un paciente puede ser muy voluminosa (en el caso mÃs extremo historia clÚnica electrµnica completa), por tanto, no es recomendable materializar toda ella, sino que es mÃs conveniente el consultar sµlo aquella que es necesaria. Por otro lado, el esquema global de un mediador se suele construir siguiendo una metodologÚa "top-down" de acuerdo con las necesidades de informaciµn de los usuarios globales. Es por esto, que se puede entender a los mediadores como servicios que se construyen y se ponen a disposiciµn de los clientes. 3. El Sistema MIDAS El sistema MIDAS se encarga de atender cualquier peticiµn de informaciµn clÚnica-administrativa sobre los pacientes, por tanto se sitºa entre los usuarios finales (aplicaciones) y las fuentes de datos del hospital. La comunicaciµn entre las aplicaciones cliente y MIDAS està basada en el uso de un conjunto de servicios ofertados por el servidor que son accesibles para cualquier cliente. BÃsicamente. La figura 1 muestra la arquitectura general del sistema. Los usuarios del sistema reciben la informaciµn clÚnica-administrativa de los pacientes por medio de un mensaje. El mensaje de respuesta contiene un documento XML con la informaciµn solicitada. Por tanto, es necesario poder definir plantillas de mensajes de manera sencilla y sin tener que modificar tanto el servidor como las aplicaciones clientes. Con este propµsito se ha definido un lenguaje basado en XML para la definiciµn de tales mensajes. Este lenguaje ha sido bautizado como MAD. Con este lenguaje es posible especificar la siguiente informaciµn: fuente o fuentes de datos que contienen la informaciµn necesaria para crear instancias de mensajes, informaciµn que se va a extraer de esas fuentes y el etiquetado y estructura del documento XML resultante (MAD permite crear estructuras anidadas sin limite de profundidad), parÃmetros que acepta el mensaje y las combinaciones vÃlidas de Õstos. Por ejemplo, para acceder a los anÃlisis de laboratorio de los pacientes, definirÚamos un mensajes en el cual la ºnica fuente de datos relevante serÚa la base de datos instalada en el laboratorio, la informaciµn a extraer serÚan los campos de la base de datos que contienen el tipo y resultado de las pruebas y estructurarÚamos el mensaje de respuesta en dos bloques con etiquetas "bioquÚmica estÃndar" y "inmunologÚa" cada una de ellas con sus respectivas pruebas.
Figura 1: Arquitectura MIDAS. El sistema para realizar su trabajo hace uso de un diccionario de datos, que contiene las definiciones de los mensajes y la descripciµn de las fuentes de datos conectadas al sistema. Las fuentes de datos pueden ser de diferente naturaleza. El repositorio contiene la informaciµn necesaria para acceder a ellas, por ejemplo, direcciones de red, adaptador a utilizar para el acceso a datos o informaciµn de autentificaciµn en los sistemas donde se alojan. En el caso del Hospital la Fe la mayorÚa de la informaciµn esta almacenada en bases de datos relacionales, aunque tambiÕn se pueden encontrar informes en archivos de texto que se acceden a travÕs de FTP, imÃgenes en sistemas PACS o datos que se obtienen a travÕs de servicios de mensajerÚa. Para acceder a estas fuentes se han diseþado unos adaptadores especÚficos. MIDAS tiene cuatro componentes bÃsicos como se muestra en la figura 1. Cuando se inicia el sistema el parseador analiza los mensajes disponibles en el diccionario de datos y crea una estructura interna (Ãrbol) que simula la estructura del mensaje respuesta, en la que cada nodo se corresponderÚa con un elemento XML, ya sea este simple o compuesto. Si es un elemento simple, el nodo correspondiente es una hoja del Ãrbol y tiene asociada una expresiµn que involucra informaciµn procedente de las fuentes de datos. Un elemento compuesto, ºnicamente define cµmo estructurar los datos en el mensaje respuesta y puede tener asociada una plantilla de consulta para obtener la informaciµn a la que hacen referencia sus nodos descendientes. Cuando el usuario del sistema realiza una peticiµn de instanciaciµn de uno de los mensajes para un caso concreto (p.ej. datos demogrÃficos de un paciente o resultados de un anÃlisis), el generador de XML interpreta el Ãrbol construido previamente y haciendo uso del generador de consultas crea las consultas necesarias para obtener la informaciµn requerida. A continuaciµn, estas consultas son lanzadas y gestionadas por el procesador de consultas. Una vez obtenidos los datos el generador de XML construye con ellos el mensaje respuesta que se envÚa finalmente al cliente. 4. MÕtodos Teniendo en cuenta como prerrequisito que el sistema ha de ser accesible para diferentes aplicaciones que se ejecutan en distintos sistemas operativos y arquitecturas el uso de tecnologÚas abiertas se convierte en la opciµn mÃs adecuada para la comunicaciµn de la informaciµn. De las tecnologÚas disponibles se opta por XML [5] para la construcciµn de los mensajes y la definiciµn tanto de estos como de las fuentes de datos del sistema y de Webservices [6] para la comunicaciµn de la informaciµn. BÃsicamente un WebService es un servicio que implementa una colecciµn de operaciones que pueden ser invocadas a travÕs de la red utilizando mensajerÚa estÃndar basada en XML. Estas tecnologÚas estÃn teniendo una gran difusiµn y existen gran cantidad de librerÚas y utilidades para su uso en la mayorÚa de los entornos de desarrollo existentes. De esta manera, podemos elegir entre una gran variedad de plataformas a la hora de implementar aplicaciones que hagan uso de la arquitectura MIDAS. En nuestro caso, para el diseþo del visor de historia clÚnica, se ha utilizado JAVA como lenguaje de programaciµn. 5. Conclusiones y trabajo futuro La implantaciµn de MIDAS se ha realizado satisfactoriamente en el hospital y se ha demostrado la viabilidad de este tipo de arquitectura en un entorno con sistemas de informaciµn tan heterogÕneos. Una de las principales ventajas del sistema es la posibilidad de tener un acceso uniforme y centralizado a las distintas fuentes de informaciµn clÚnica, lo cual facilita enormemente entre otras cosas el desarrollo de nuevas aplicaciones, el mantenimiento y la auditoria de acceso a los datos. Las ventajas del sistema serian aºn mÃs importante si el etiquetado y estructura de los mensajes siguiesen algºn estÃndar para la comunicaciµn de informaciµn clÚnica como el EN13606 del ComitÕ TÕcnico 251 del ComitÕ Europeo de Normalizaciµn (CEN/TC251) [7]. Como tareas futuras se ha planteado aþadir mecanismos de encriptaciµn y autentificaciµn mÃs robustos y diseþar herramientas grÃficas que faciliten la configuraciµn de la aplicaciµn y de los diccionarios de datos. 6. BibliografÚa Maldonado JA, Robles,M, Crespo P. Integration of distributed healthcare records: publishing legacy data as XML documents compliant with CEN/TC251 ENV13606.Proceedings of the 16th IEEE Symposium on Computer Based Medical Systems. IEEE Computer Society Press, pp. 213-218 (2004). Maldonado, J.A., Robles, M., Cano, C., Crespo, P. Integraciµn de sistemas de informaciµn hospitalarios: utilizaciµn del estÃndar de arquitectura de historia clÚnica electrµnica ENV13606 del CEN/TC251, 34, 44-50 (2002). Bouguettaya, A., Benatallah, B., Elmagarmid, A. Interconnecting heterogeneous information systems. Kluwer Academic Publishers (1998). Wiederhold, G. Mediators in the Architecture of Future Information Systems. Computer 25(3), 38-49 (1992).
|
|
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripciµn SEIS] [Bºsquedas] |
|
Copyright SEISˋ 1997-2004. |