INFORSALUD 2004
Madrid, 24-26 de marzo de 2004
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripciµn SEIS] [Bºsquedas]
|
INFORSALUD 2004 |
La Cooperaciµn entre Redes Sanitarias |
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripciµn SEIS] [Bºsquedas] |
||
|
¢Cµmo llegar a la sede del Congreso? SecretarÚa TÕcnica: CEFIC
|
USO DE TECNOLOGëAS DE AGENTES PARA LA INTEGRACIÆN DE BASES DE DATOS CLëNICAS Y GENèTICAS BAHILLO, R., GARCëA-REMESAL, M., PèREZ, D., ALONSO-CALVO, R., ROMERO, B., LLORENTE, JC., MARTINEZ, G., BARBADO, V., MORAL, C., MARTINEZ-AGRA, A., MARTIN-SêNCHEZ, F. 2, SOUSA, A. 3, OLIVEIRA, I.C. 3, MAOJO, V.
Resumen. El objetivo del sistema INFOGENMED es facilitar la recuperaciµn homogÕnea de informaciµn, a travÕs de Internet, proporcionando un acceso unificado a mºltiples y diversas bases de datos relacionales remotas ya existentes. La investigaciµn desarrollada parte de la idea de que un conjunto de bases de datos heterogÕneas forma un espacio de informaciµn ºnico. La arquitectura del sistema trata de facilitar al usuario el acceso a toda la informaciµn disponible, a la que se tiene acceso a travÕs de las bases de datos registradas en el sistema, de forma intuitiva y directa. El sistema pretende, por un lado, permitir la integraciµn de diferentes esquemas lµgicos de bases de datos relacionales, y por otro, establecer una arquitectura distribuida estÃndar, no condicionada a productos propietarios, que facilite la conexiµn de cualquier base de datos. Como infraestructura tecnolµgica se propone el uso de agentes inteligentes, que dan al sistema mayor flexibilidad y eficiencia, facilitando las tareas de integraciµn y bºsquedas, aspectos desarrollados en el artÚculo.
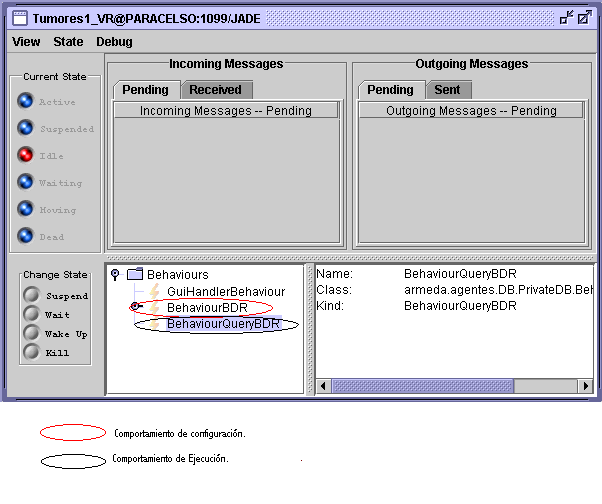
1. Introducciµn La informaciµn clÚnica y genµmica ha estado, hasta ahora, almacenada en sistemas completamente heterogÕneos [1]. Al integrar bases de datos heterogÕneas, se consideran dos niveles de heterogeneidad: (1) plataformas tecnolµgicas diferentes (mÃquinas, sistemas operativos, y sistemas gestores de bases de datos), y (2) esquemas de base de datos diferentes. El punto (1) se refiere al aspecto de bºsqueda de soluciones tÕcnicas, mientras que el (2) se refiere a aspectos teµricos o conceptuales. Esto quiere decir que aunque bases de datos diferentes pueden contener informaciµn relativa al mismo dominio, usualmente tendrÃn diferentes esquemas. Por ello, es necesario crear un "mapping" o correspondencia entre el esquema fÚsico de una base de datos y un esquema conceptual (en este artÚculo, basado en ontologÚas), creado mediante la utilizaciµn de terminologÚa estÃndar asociada a un dominio (el dominio biomÕdico). La idea principal es que unidades de informaciµn similares almacenadas en diferentes bases de datos pueden ser nombradas de la misma manera en sus respectivos esquemas conceptuales de mapping. Este hecho permitirÚa la unificaciµn automÃtica de dos o mÃs esquemas conceptuales que contengan entidades, creando un nuevo repositorio virtual de unificaciµn que engloba la informaciµn de sus repositorios hijo. Los procesos de mapping y unificaciµn permiten crear una organizaciµn taxonµmica es decir, una relaciµn de contenciµn o subsunciµn del espacio de informaciµn disponible mediante la creaciµn de una jerarquÚa de repositorios virtuales. Estos repositorios virtuales ya sean de mapping o de unificaciµn facilitarÚan el acceso unificado a diferentes bases de datos remotas. 2. MÕtodos La soluciµn propuesta para gestionar la heterogeneidad de los esquemas de las bases de datos se afronta mediante una teorÚa de unificaciµn basada en la creaciµn de un esquema virtual unificado que integre los diferentes esquemas locales de las bases de datos. El esquema unificado proporciona una visiµn homogÕnea del espacio de informaciµn, que està compuesto por los datos existentes en las diversas bases de datos remotas [2]. El proceso de generaciµn del esquema global conlleva la realizaciµn de dos procesos: un proceso denominado de "mapping" cuyo objetivo es traducir los esquema internos de las bases de datos a esquemas conceptuales auto descriptivos, y un segundo proceso, denominado de unificaciµn, que permite la integraciµn de distintos esquemas conceptuales obtenidos previamente [3][4]. El primero, debido a su carÃcter semÃntico deberà llevarse a cabo con ayuda humana, mientras que el segundo se llevarà a cabo de forma automÃtica. Al realizar la unificaciµn e integraciµn de bases de datos deben ser considerados tres niveles de heterogeneidad: (1) Heterogeneidad de la plataforma tecnolµgica: diferentes sistemas hardware y sistemas operativos, (2) Heterogeneidad del Sistema Gestor de Base de Datos (en adelante, SGBD), (3) Heterogeneidad del esquema de la base de datos y del modelo de datos conceptual asociado. INFOGENMED introduce una soluciµn a los dos primeros puntos mediante una arquitectura basada en agentes inteligentes, que facilita la comunicaciµn entre mµdulos. Asimismo, establece un sistema altamente flexible con respecto a la integraciµn de nuevos servicios y bases de datos en el futuro. Cada una de las bases de datos va a estar gestionada por un agente, por lo que si queremos aþadir alguna nueva, basta con aþadir un agente mÃs al sistema. Existen diferentes clasificaciones dependiendo de varios rasgos de los agentes. La que interesa a este proyecto es la clasificaciµn entre agentes estÃticos y agentes mµviles. Los agentes estÃticos (usados en este proyecto) son entidades con ejecuciµn limitada al sistema donde se inicia. Interactºa con entidades locales, ya sean otros agentes, programa o usuarios. Pero tambiÕn puede interactuar con recursos remotos vÚa CORBA, RMI, RPC. Los agentes mµviles son agentes con capacidad de movimiento que interactºan directamente con entidades locales o remotas, y si son remotas el agente migrarà hacÚa la mÃquina contenedora. Un agente es una entidad software que se comunica con otros agentes mediante una plataforma comºn. Esta plataforma puede estar distribuida en varias mÃquinas. Solamente una aplicaciµn Java y, por tanto, una ºnica MÃquina Virtual Java, es ejecutada en cada mÃquina. Los agentes estÃn implementados como threads Java y residen en Contenedores de Agentes los cuales proporcionan soporte para la ejecuciµn de los agentes. Las principales funciones que realizan son proporcionar al administrador del sistema un mÕtodo fÃcil para unir una nueva base de datos al sistema y desarrollar APIs para que el usuario pueda realizar preguntas al sistema y para que pueda recuperar los datos resultantes de las mismas. 3. Resultados A continuaciµn se muestra una pantalla con los comportamientos activos de un agente reciÕn creado, uno de ejecuciµn y otro de configuraciµn.
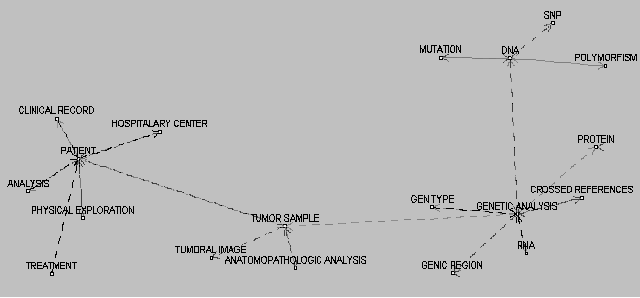
Figura 1. Ejemplo de pantalla mostrando los comportamientos de un agente Los agentes facilitan la infraestructura necesaria para conectar los diversos subsistemas de INFOGENMED. Para realizar una bºsqueda de prueba se han tomado dos bases de datos mÕdicas con contenidos relacionados con tumores. Para la representaciµn de ontologÚas, que son usados en INFOGENMED para varias tareas, se ha usado el lenguaje DAML+OIL, tanto para representar los esquemas virtuales (obtenidos gracias al mapping, que se muestra en la figura 2, y a la unificaciµn) como para representar los resultados de una consulta, es decir, instancias de clases DAML+OIL. Una parte importante aportada por este proyecto ha sido el hecho de que se acepte cualquier tipo de sintaxis SQL. El sistema cogerà un fichero de configuraciµn XML para conseguir la sintaxis adecuada.
Figura 2. Ejemplo de mapping entre dos bases de datos en el caso de prueba 4. Conclusiones La estandarizaciµn de mÕtodos y su sencillez de uso hacen de la World Wide Web (WWW o Web) el medio idµneo para el acceso e intercambio de informaciµn [5]. Sin embargo, la informaciµn ya existente en la bases de datos relacionales tradicionales no estÃ, a priori, accesible desde la Web. Para su recuperaciµn se emplean programas PHP, ASP, JSP, que resuelven los accesos y convierten el resultado de una peticiµn en documentos HTML. El problema asociado a este mÕtodo es la imposibilidad de realizar bºsquedas de informaciµn no sµlo en una base de datos de la red, sino en varias. Para realizar esta tarea hoy en dÚa, el usuario debe acceder manualmente a todas y cada una de las bases de datos en las que està interesado, de manera que pueda buscar toda la informaciµn existente. Con el sistema INFOGENMED y las tecnologÚas de agentes y ontologÚas se pretende crear un nuevo mÕtodo de integraciµn de bases de datos clÚnicas y genÕticas.
Agradecimientos Esta investigaciµn ha sido apoyada por el proyecto INFOGENMED y la Network of Excellence INFOBIOMED de la Comisiµn Europea, por el Ministerio de Sanidad y Consumo (red INBIOMED) y el Ministerio de Ciencia y TecnologÚa, (TIC 2002-04444-C02-02.
Referencias [1] Martin, F. (project coordinator). 2002. BIOINFOMED. Prospective Analysis on the Relationships and Synergy between Medical Informatics and Bioinformatics. European Commission. [2] Billhardt, H., J. Crespo, V. Maojo, F. MartÚn, and J.L. MatÕ. 2001.Unifying Heterogeneous Medical Databases. In Medical Data Analysis. Lecture Notes in Computer Science 2199: 54-61, edited by J. Crespo, J., V. Maojo and F. MartÚn. Springer Verlag: Heidelberg. [3] M. Garcia-Remesal, J. Crespo, A. Silva, H. Billhardt, F. Martin, J. Rodriguez-Pedrosa, V. Martin, A. Sousa, A. Babic & V. Maojo. "INFOGENMED: Integrating heterogeneous medical and genetic databases and terminologies". In: Proceedings KES 2002, Crema (Italy). September, 2002. [4] Maojo, V, Martin, Ibarrola, N, et al.: INFOGENMED: Functional Design of a Workstation for a Virtual Laboratory. Proceedings of the AMIA Annual Fall Simposium. Washington, USA. Nov. 1999 [5] MartÚn, F., Maojo, V. and G. Lµpez-Campos. 2002. Challenges in integrating genomic data into the different health information levels. Methods Inf Med. 2002;41(1):pp. 25-30.
|
|
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripciµn SEIS] [Bºsquedas] |
|
Copyright SEISˋ 1997-2004. |