INFORSALUD 2004
Madrid, 24-26 de marzo de 2004
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas]
|
INFORSALUD 2004 |
La Cooperación entre Redes Sanitarias |
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas] |
||
|
żCómo llegar a la sede del Congreso? Secretaría Técnica: CEFIC
|
PROSPECCIÓN DE DATOS SANITARIOS: ESTUDIO DE LA INCAPACIDAD PERMANENTE M. BAENA1, R. MORALES1, S. CABUCHOLA2 1 2 Médico evaluador. Jefe de la Unidad Médica del Equipo de Valoración de Incapacidades. Dirección Provincial del Instituto Nacional de la Seguridad Social. Málaga. Espańa.Resumen. La prospección de datos (Data Mining - DM) es un proceso de extracción de información interesante (no trivial, implícita, previamente desconocida y potencialmente útil) desde datos almacenados en grandes bases de datos. Este artículo se desarrolla con el fin de realizar una revisión de la situación actual de la prospección de datos y sus diferentes fases, mostrando los resultados de la aplicación de la metodología CRISP-DM a un proyecto real de prospección de datos: ``Prospección de datos de Incapacidad Permanente''. Se presenta un resumen del informe final de la aplicación de la metodología, en este informe quedan recogidos los resultados de cada una de las fases. Con esto se pretende dar una visión general de lo que sería el desarrollo de un proceso de prospección. Este trabajo es un prototipo de aplicación al estudio de Incapacidad Permanente. El resultado final ha sido un software que estima si una persona tiene derecho a Incapacidad Permanente.
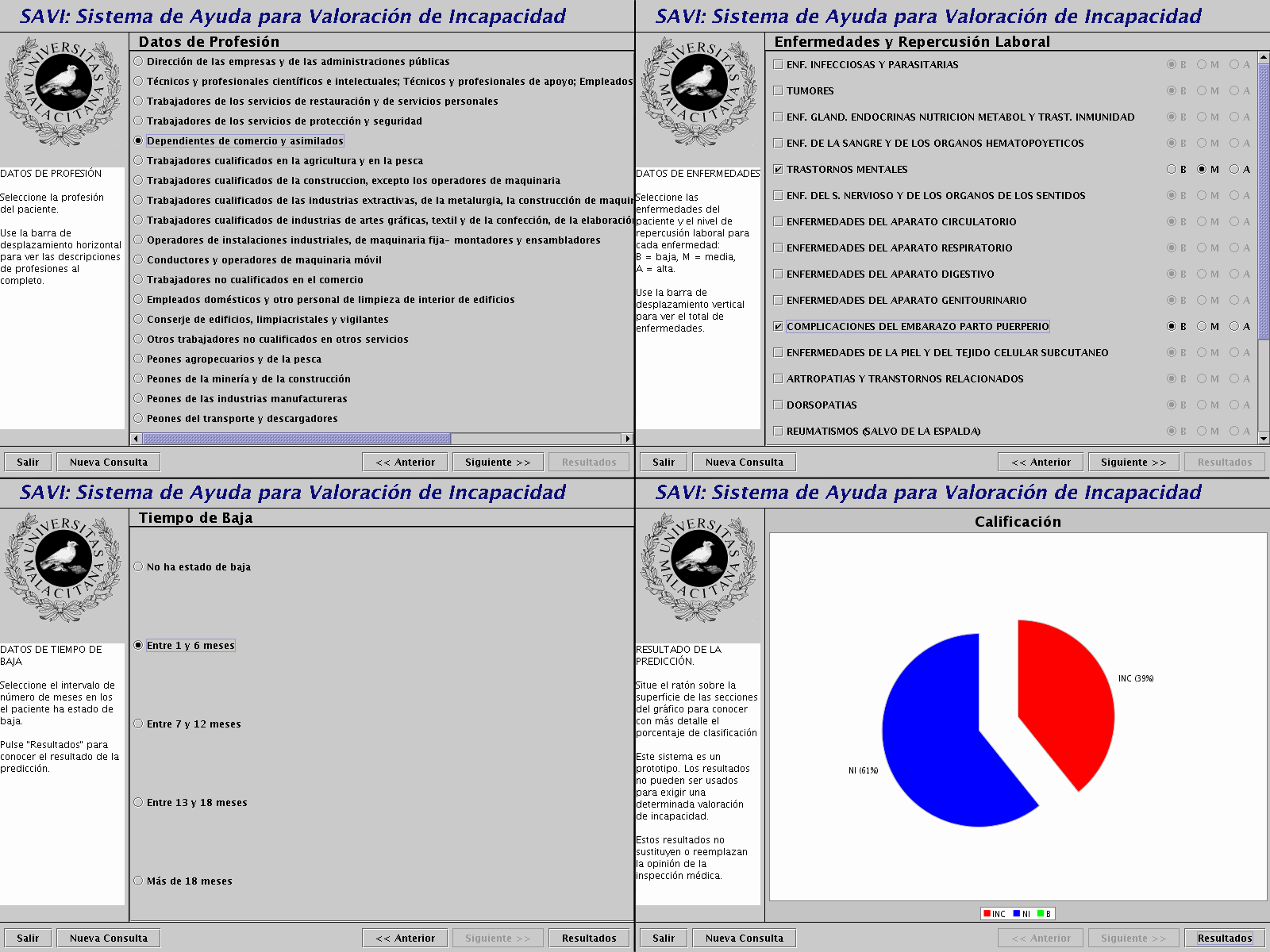
1. Introducción La automatización de procesos se integra cada día más en nuestra sociedad. Del resultado de esta automatización se obtienen datos "informatizados" que en ocasiones son almacenados y en ocasiones descartados. Dado el abaratamiento de la tecnología de almacenamiento lo más frecuente suele ser almacenar la mayor cantidad de datos posible. Esta recolección de datos automática producen tremendas cantidades de datos almacenados en bases de datos, almacenes de datos (data warehouses) y otros repositorios de información. La prospección de datos [1] nace con el fin de extraer información interesante desde datos almacenados en grandes bases de datos. Con "información interesante" nos referimos a no trivial, implícita, previamente desconocida y potencialmente útil. La prospección de datos combina técnicas de estadística clásica y técnicas de inteligencia artificial como aprendizaje estadístico y computacional. Al hablar de prospección de datos debemos hablar del proceso de prospección. Existen diferentes metodologías, la más aceptada y por la que nos hemos decantado es la guía CRISP-DM [2]. En ella se define un modelo jerárquico de tareas a cuatro niveles de abstracción: En el nivel más alto el proceso se organiza en un número de fases; cada fase consiste en varias tareas genéricas de segundo nivel. Las tareas específicas solucionan tareas genéricas en situaciones específicas. Y los procesos son cada una de las aplicaciones de las tareas específicas a datos. 2. El Proceso CRISP-DM El modelo de proceso provee una visión global del ciclo de vida de este tipo de proyectos. Este ciclo de vida contiene las fases del proyecto, sus respectivas tareas y las relaciones entre estas tareas. El interés de esta sección es describir, a nivel de fases, el ciclo de vida de la guía CRISP-DM [2]. El ciclo de vida de un proyecto de prospección de datos consta de seis fases (figura 1). La secuencia de realización de estas fases no es estricta, se requieren movimientos de una fase a otra en base a los resultados obtenidos durante el proceso. Las flechas indican las dependencias más frecuentes entre las diferentes fases. El círculo exterior simboliza la naturaleza cíclica de la prospección de datos. La prospección de datos no concluye cuando se encuentra una solución, pues esta solución puede abrir nuevas puertas a explorar. La iteración en el proceso beneficia la experiencia adquirida en la iteración anterior. La fase inicial del proceso de prospección de datos (comprensión del problema) está enfocada en la comprensión de los objetivos y requisitos del proyecto desde una perspectiva del cliente. En la comprensión de datos se recopilan los datos necesarios para el desarrollo del proyecto, se ofrece información de la estructura de estos datos, de su calidad y subconjuntos de interés. En la preparación de datos se cubren todas las actividades para construir los conjuntos de datos finales (datos que serán utilizados en las herramientas de modelado) a partir de los datos en bruto iniciales. En el modelado se seleccionan y aplican diferentes técnicas y sus parámetros son calibrados a los valores óptimos. Antes de proceder con el desarrollo final del modelo, es importante una evaluación más profunda y una revisión de los pasos seguidos en su construcción para asegurar que sus propiedades están dentro de los objetivos del proyecto. 3. Proceso de Prospección de Incapacidad Permanente (IP) En esta sección se exponen los resultados de la aplicación de la metodología CRISP-DM a datos de Incapacidad Permanente. Se presenta un resumen del informe final (trabajo completo en [3]), en el que quedan recogidos los resultados de cada una de las fases. Con esto se pretende dar una visión general de lo que sería el desarrollo de un proceso de prospección. No pretende ser un estudio exhaustivo de la Incapacidad Permanente, pues el conjunto de datos usado es limitado (978 expedientes). En los siguientes puntos se presenta el resultado de cada una de las fases del proceso: Comprensión del Problema: El Real Decreto 1300/95 establece las competencias que en materia de incapacidad laboral permanente le corresponde al Instituto Nacional de la Seguridad Social (INSS). Dicho texto legal crea en las Direcciones Provinciales del INSS los Equipos de Valoración de Incapacidades (EVI). La incapacidad permanente (IP), en su modalidad contributiva, tiene en cuenta la alteración continuada de la salud y, fundamentalmente, la incidencia que dicha alteración tiene en la realización de la actividad profesional. Tiene un perfil exclusivamente profesional y su calificación debe obviar toda referencia a otras circunstancias (socio-económicas, de edad, familiares, etc.). Se clasifica conforme a los siguientes grados: IP Parcial, IP Total, IP Absoluta, Gran Invalidez y Lesiones Permanentes No Invalidantes. En base a lo expuesto, los objetivos del problema son dos: aportar al INSS una serie de datos que permitan a los Médicos Inspectores tener una aproximación, previa a la evaluación individualizada, del resultado que cabe esperar en cada uno de los expedientes de IP y permitir satisfacer las expectativas de los beneficiarios de la Seguridad Social. Se pretende que los asegurados conozcan en cada momento, si su situación clínico-laboral es susceptible de generar una IP con el menor margen de error posible. Comprensión de datos: La tarea principal de esta fase es la Descripción de datos. En esta tarea se examinan, a groso modo, las propiedades de los datos capturados. En el informe se describen el tamańo de los datos (análisis volumétrico) y su formato, se realizan medidas estadísticas básicas y se analiza el significado de los resultados, por ejemplo la relevancia de un atributo para los objetivos y su comparación con la opinión del experto del dominio. La Unidad Médica del EVI elabora los Informes Médicos de Síntesis (IMS) como documento preceptivo para evaluar la discapacidad laboral. Por otro lado, las actas resultantes de las sesiones celebradas por el EVI constan de la propuesta del grado de invalidez permanente, la contingencia determinante y si hay que realizar revisión o no y en que fecha. Los datos se han obtenido, por personal autorizado, tanto de los IMS como de las actas de las sesiones garantizando la privacidad. Algunos de los datos, como la edad o el sexo, han sido extraídos directamente de estos documentos, otros, como la repercusión laboral, son datos calculados, capturados por personal cualificado. Preparación de datos: Un subconjunto de los datos adquiridos en fases previas es seleccionado, basándose en características recalcadas en dichas fases, y se crean conjuntos de datos válidos para la aplicación de las técnicas de prospección en la fase de modelado. Modelado: En esta fase se seleccionan las técnicas de modelado, se aplican sobre los conjuntos de datos y se calibran sus parámetros a valores óptimos. Particularmente, en el proceso de prospección de IP, hemos utilizado árboles de decisión y reglas de asociación. Evaluación: En las fases previas (principalmente en la fase de modelado) se completa la evaluación de la precisión de los modelos construidos. En esta fase se evalúan los modelos respecto a los objetivos a solventar del problema. Es cuando se tiene que decidir si existen motivos por los que los modelos generados sean deficientes. De acuerdo a la evaluación de los resultados y la revisión del proceso, se decide como proceder en el futuro. Se necesita decidir cuando finalizar el proyecto y, en caso de ser apropiado, realizar el desarrollo de software o cuando iniciar una nueva iteración del proceso o preparar nuevos proyectos de prospección de datos. Con el fin de completar los objetivos de la prospección de datos, y dado que los resultados obtenidos en los modelos lo permiten, desarrollamos el sistema SAVI, un sistema para la ayuda a la valoración de incapacidad permanente. Desarrollo: La creación del modelo no supone, generalmente, la finalización del proyecto. Así, si el propósito del modelo es incrementar el conocimiento de los datos, este conocimiento obtenido necesita organizarse y representarse de manera que pueda ser usado. Con el sistema SAVI mostramos un ejemplo de lo que se podría conseguir mediante la aplicación de procesos de prospección a datos sanitarios (ver figura 2).
Figura 2: Capturas de pantalla del sistema SAVI Referencias [1] W.J. Frawley, G. Piatetsky-Shapiro, and C. J. Matheus. Knowledge discovery in databases: an overview. In Knowledge discovery in databases, pages 1-27. 1991, AAAI Press/ MIT Press. [2] P.Chapman, J. Clinton, T. Khabaza, T. Reinartz, and R. Wirthz. The crisp-dm process model. Technical Report, CRISPDM Consortium, 1999 [3] M. Baena-García. Prospección de Datos: Estudio de diversas técnicas y su aplicación a datos sobre Incapacidad Laboral. PFC. ETSI Informática. Universidad de Málaga, 2003.
|
|
|
[Entrada] [Actividades] [Revista I+S] [Solicitud de Inscripción SEIS] [Búsquedas] |
|
Copyright SEIS© 1997-2004. |